Scrapy-基础-Shell
本文最后更新于:2021年2月5日 下午
简介
Scrapy``shell 是一个快速debug交互shell,一般被用于做数据抽取代码的测试工作,它得到的结果会和你在Python中跑出来的一样
使用
命令行启动
1 | |
这是最基本的启动方式
注意:双引号不要去除,也不要用单引号来替代
你也以用shell来加载本地文件
1 | |
- 如果使用相对路径,使用./或../开头
scrapy shell index.html并不会工作
scrapy shell index.html并不会工作原因
这并不是一个bug,shell会将index.html当成一个域名来处理,将它丢给DNS来解析,结果自然是没有正确的解析的
你也可以设置请求头来访问
1 | |
代码启动
1 | |
response参数是parse方法中的参数,self是Spider类的参数
在适当的地方启用shell能达到很好的目的(比如说使用catch.....except捕获错误以后,看看为什么解析错误报错之类)
信息
捷径
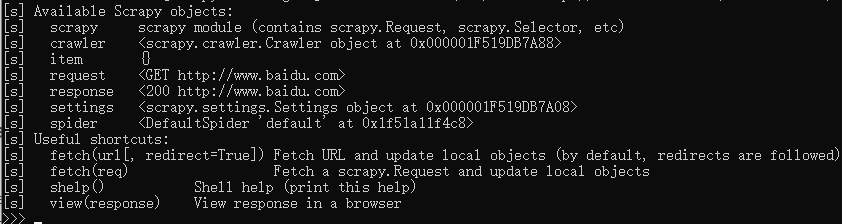
在你打开shell之后,会显示一些捷径提示,你可以在shell中使用这些捷径来快速做事
可用的Scrapy对象
Shell中有一些自动创建的对象
crawler- 当前crawler对象spider- 当前url的spider对象request- 最后请求的页面对象的Request对象. 你可以使用replace()来更改这个对象.你也可以用fetch捷径来接收一个新的requestresponse- 装则响应的Response对象settings- Scrapy设置
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!