Javascript-基础-1
本文最后更新于:2021年1月26日 下午
Javascript信息
JavaScript这个名字的原意是“很像Java的脚本语言”
语言信息
- 轻量级脚本语言
它不具备开发操作系统的能力,而是只用来编写控制其他大型应用程序(比如浏览器)的“脚本” - 嵌入式(embedded)语言
它本身提供的核心语法不算很多,只能用来做一些数学和逻辑运算。不提供任何与I/O相关的API,都要靠宿主环境(host)提供,所以JavaScript只合适嵌入更大型的应用程序环境,去调用宿主环境提供的底层API
最常见的环境就是浏览器,另外还有服务器环境,也就是 Node 项目。 - 弱类型
- 解释型 或 即时编译型
JavaScript 基于原型编程、多范式的动态脚本语言,并且支持面向对象、命令式和声明式(如函数式编程)风格
特点
语法灵活
既支持类似 C 语言清晰的过程式编程,也支持灵活的函数式编程,可以用来写并发处理(concurrent)
这些语法特性已经被证明非常强大,可以用于许多场合,尤其适用异步编程
JavaScript 的所有值都是对象,这为程序员提供了灵活性和便利性。因为你可以很方便地、按照需要随时创造数据结构,不用进行麻烦的预定义
支持编译运行
虽然是一种解释型语言,但是在现代浏览器中,JavaScript 都是编译后运行。编译后,程序会被高度优化,运行效率接近二进制程序
事件驱动和非阻塞式设计
JavaScript 程序可以采用事件驱动(event-driven)和非阻塞式(non-blocking)设计,在服务器端适合高并发环境,普通的硬件就可以承受很大的访问量
语言历史
起源
网景(Netscape)公司开发了 Navigator 浏览器,发现浏览器应该需要脚本语言来实现一些简单的功能
此时Sum公司JAVA语言问世,并且相当成功。网景公司决定于Sum公司合作,让浏览器支持JAVA
网景公司研究了一段时间,发现JAVA太重,不合适,但决定未来浏览器脚本语言语法要接近JAVA
网景公司雇佣了 Brendan Eich 大佬来开发这种新的语言Brendan Eich 大佬以 Scheme 语言为蓝本,花费10天时间,完成了这个语言的第一版
- 基本语法:借鉴
C语言和Java语言 - 数据结构:借鉴
Java语言,包括将值分成原始值和对象两大类 - 函数的用法:借鉴
Scheme语言和Awk语言,将函数当作第一等公民,并引入闭包 - 原型继承模型:借鉴
Self语言(Smalltalk的一种变种) - 正则表达式:借鉴
Perl语言 - 字符串和数组处理:借鉴
Python语言
这个脚本语言,最初名字叫做 Mocha,1995年9月改为 LiveScript。12月,网景公司与 Sun公司 达成协议,后者允许将这种语言叫做 JavaScript
JavaScript 与 ECMAScript
1996年8月,微软模仿 JavaScript 开发了一种相近的语言,取名为JScript(JavaScript 是 网景公司 的注册商标,微软不能用),内置于 IE3.0。网景公司面临丧失浏览器脚本语言的主导权的局面
1996年11月,网景公司决定将 JavaScript 提交给国际标准化组织 ECMA(European Computer Manufacturers Association),希望 JavaScript 能够成为国际标准,以此抵抗微软。ECMA 的39号技术委员会(Technical Committee 39)负责制定和审核这个标准,成员由业内的大公司派出的工程师组成
1997年7月,ECMA组织发布262号标准文件(ECMA-262)的第一版,规定了浏览器脚本语言的标准,并将这种语言称为 ECMAScript。这个版本就是 ECMAScript 1.0 版
之所以不叫 JavaScript,
一方面是由于商标的关系,Java 是 Sun 公司的商标,根据授权协议,只有 网景公司可以合法地使用 JavaScript 这个名字, JavaScript 已经被 网景公司注册为商标
另一方面也是想体现这门语言的制定者是 ECMA,不是 网景公司,这样有利于保证这门语言的开放性和中立性。因此,ECMAScript 和 JavaScript 的关系是,前者是后者的规格,后者是前者的一种实现。在日常场合,这两个词是可以互换的
更新迭代
1997年7月,ECMAScript 1.0发布
1998年6月,ECMAScript 2.0版发布
1999年12月,ECMAScript 3.0版发布,成为 JavaScript 的通行标准,得到了广泛支持
2007年10月,ECMAScript 4.0版草案发布,对3.0版做了大幅升级,预计次年8月发布正式版本。草案发布后,由于4.0版的目标过于激进,各方对于是否通过这个标准,发生了严重分歧。以 Yahoo、Microsoft、Google 为首的大公司,反对 JavaScript 的大幅升级,主张小幅改动;以 JavaScript 创造者 Brendan Eich 为首的 Mozilla 公司,则坚持当前的草案
2008年7月,由于对于下一个版本应该包括哪些功能,各方分歧太大,争论过于激进,ECMA 开会决定,中止 ECMAScript 4.0 的开发(即废除了这个版本),将其中涉及现有功能改善的一小部分,发布为 ECMAScript 3.1,而将其他激进的设想扩大范围,放入以后的版本,由于会议的气氛,该版本的项目代号起名为 Harmony(和谐)。会后不久,ECMAScript 3.1 就改名为 ECMAScript 5。
2009年12月,ECMAScript 5.0版 正式发布。Harmony 项目则一分为二,一些较为可行的设想定名为 JavaScript.next 继续开发,后来演变成 ECMAScript 6;一些不是很成熟的设想,则被视为 JavaScript.next.next,在更远的将来再考虑推出。TC39 的总体考虑是,ECMAScript 5 与 ECMAScript 3 基本保持兼容,较大的语法修正和新功能加入,将由 JavaScript.next 完成。当时,JavaScript.next 指的是ECMAScript 6。第六版发布以后,将指 ECMAScript 7。TC39 预计,ECMAScript 5 会在2013年的年中成为 JavaScript 开发的主流标准,并在此后五年中一直保持这个位置。
2011年6月,ECMAScript 5.1版发布,并且成为 ISO 国际标准(ISO/IEC 16262:2011)。到了2012年底,所有主要浏览器都支持 ECMAScript 5.1版的全部功能。
2013年3月,ECMAScript 6 草案冻结,不再添加新功能。新的功能设想将被放到 ECMAScript 7
2013年12月,ECMAScript 6 草案发布
2015年6月,ECMAScript 6 正式发布,并且更名为 ECMAScript2015。这是因为 TC39 委员会计划,以后每年发布一个 ECMAScript 的版本,下一个版本在2016年发布,称为 ECMAScript 2016,2017年发布 ECMAScript 2017,以此类推
常见应用
- 前端
React,Vue,Angular - 后端
Node.js - 桌面端
Electron - 物联网
Arduino - 数据库
MongoDB - 移动端
React Native
语法基础
语句 与 表达式
JavaScript 程序的执行单位为行(line),也就是一行一行地执行。一般情况下,每一行就是一个语句
语句(statement)是为了完成某种任务而进行的操作,一般情况下不需要返回值
表达式(expression),指一个为了得到返回值的计算式
比如下面的代码
1 | |
这是 一行 赋值 语句,这条语句先用var命令,声明了变量a 然后将 表达式 1 + 3 的运算结果赋值给变量a
凡是 JavaScript 语言中预期为值的地方,都可以使用表达式
比如,赋值语句的等号右边,预期是一个值,因此可以放置各种表达式
语句以分号结尾,一个分号就表示一个语句结束。多个语句可以写在一行内
1 | |
分号前面可以没有任何内容,JavaScript 引擎将其视为 空语句
1 | |
表达式 不需要分号 结尾。一旦在表达式后面添加分号,则 JavaScript 引擎就将表达式视为 语句,这样会产生一些没有任何意义的 语句
1 | |
上面两行语句只是单纯地产生一个值,并没有任何实际的意义
变量
变量 是对 “值” 的具名引用
变量就是为“值”起名,然后引用这个名字,就等同于引用这个值。变量的名字就是变量名
声明与赋值
注意,JavaScript 的变量名区分大小写,A和a是两个不同的变量
1 | |
上面的代码先声明变量a,然后在变量a与数值1之间建立引用关系,称为将数值1“赋值”给变量a
以后,引用变量名a就会得到数值1。最前面的var,是变量声明命令。它表示通知解释引擎,要创建一个变量a
变量的 声明 和 赋值,是分开的两个步骤,上面的代码将它们合在了一起,实际的步骤是下面这样
1 | |
可以在同一条 var 命令中声明多个变量
1 | |
只声明不赋值的变量
如果 只是声明变量 而 没有赋值,则该变量的值是undefinedundefined是一个特殊的值,表示“无定义”
1 | |
注意:无定义与空是完全不同的
不使用命令的变量声明与赋值
如果变量赋值的时候,忘了写var命令,这条语句也是有效的
1 | |
但不写var的做法,不利于表达意图,而且容易不知不觉地创建全局变量,所以建议总是使用 var 命令声明变量
动态语言特性JavaScript 是一种动态类型语言,也就是说,变量的类型没有限制,变量可以随时更改类型。
1 | |
上面代码中,变量a起先被赋值为一个数值,后来又被重新赋值为一个字符串
重复声明
如果使用var重新声明一个已经存在的变量,是无效的
1 | |
上面代码中,变量x声明了两次,但第二次声明是无效的
但是,如果第二次声明的时候还进行了赋值,则会覆盖掉前面的值
1 | |
这是由于声明和赋值是两个操作,声明无效了不会导致赋值无效
上面的代码相当于
1 | |
变量提升 Hoisting
JavaScript 引擎的工作方式是,先解析代码,获取所有被声明的变量,然后再一行一行地运行
这造成的结果,就是所有的变量的声明语句,都会被提升到代码的头部,这就叫做 变量提升(hoisting)
1 | |
上面代码首先使用console.log方法,在控制台(console)显示变量a的值。这时变量a还没有声明和赋值,所以这是一种错误的做法,但是实际上不会报错。因为存在变量提升,真正运行的是下面的代码
1 | |
最后的结果是显示undefined,表示变量a已声明,但还未赋值。
标识符 Identifier
标识符(identifier)指的是用来识别各种值的合法名称JavaScript 语言的标识符对大小写敏感,所以a和A是两个不同的标识符
标识符有一套命名规则,不符合规则的就是非法标识符。JavaScript引擎遇到非法标识符会报错
标识符命名规则:
- 第一个字符,可以是任意
Unicode字母(包括英文字母和其他语言的字母),以及美元符号($)和下划线(_) - 第二个字符及后面的字符,除了
Unicode字母、美元符号和下划线,还可以用数字0-9
由于Unicode字符里存在中文字符,所以中文变量也是合法的
和其它语言类似,JavaScript 有一些保留字,不能用作标识符arguments、break、case、catch、class、const、continue、debugger、default、delete、do、else、enum、eval、export、extends、false、finally、for、function、if、implements、import、in、instanceof、interface、let、new、null、package、private、protected、public、return、static、super、switch、this、throw、true、try、typeof、var、void、while、with、yield
注释
源码中被 JavaScript 引擎忽略的部分就叫做注释,它的作用是对代码进行解释JavaScript 提供两种注释的写法
单行注释,用//起头;多行注释,放在/*和*/之间
1 | |
不推荐使用的 HTML注释
由于历史上 JavaScript 可以兼容 HTML 代码的注释,所以<!--和-->也被视为合法的单行注释
1 | |
需要注意的是,-->只有在行首,才会被当成单行注释,否则会当作正常的运算
1 | |
上面代码中,n --> 0实际上会当作n-- > 0,因此输出2、1、0
区块 Block
JavaScript 使用大括号,将多个相关的语句组合在一起,称为“区块”(block)
对于var命令来说,JavaScript 的区块不构成单独的作用域(scope)
1 | |
上面代码在区块内部,使用var命令声明并赋值了变量a,然后在区块外部,变量a依然有效,区块对于var命令不构成单独的作用域,与不使用区块的情况没有任何区别
在 JavaScript 语言中,单独使用区块并不常见,区块往往用来构成其他更复杂的语法结构,比如for、if、while、function等
条件判断结构
JavaScript 提供if结构和switch结构,完成条件判断,即只有满足预设的条件,才会执行相应的语句
if 结构
if结构先判断一个表达式的布尔值,然后根据布尔值的真伪,执行不同的语句
1 | |
“布尔值”往往由一个条件表达式产生的,必须放在圆括号中,表示对表达式求值
如果表达式的求值结果为true,就执行紧跟在后面的语句;如果结果为false,则跳过紧跟在后面的语句
1 | |
上面代码表示,只有在m等于3时,才会将其值加上1。
这种写法要求条件表达式后面只能有一个语句。如果想执行多个语句,必须在if的条件判断之后,加上大括号,表示代码块(多个语句合并成一个语句)
1 | |
建议总是在if语句中使用大括号,因为这样方便插入语句
if…else 结构
if代码块后面,还可以跟一个else代码块,表示不满足条件时,所要执行的代码
1 | |
上面代码判断变量m是否等于3,如果等于就执行if代码块,否则执行else代码块
对同一个变量进行多次判断时,多个if...else语句可以连写在一起。
1 | |
else代码块总是与离自己最近的那个if语句配对
1 | |
上面代码不会有任何输出,else代码块不会得到执行,因为它跟着的是最近的那个if语句,相当于下面这样。
1 | |
switch 结构
多个if...else连在一起使用的时候,可以转为使用更方便的switch结构
1 | |
上面代码根据变量fruit的值,选择执行相应的case
如果所有case都不符合,则执行最后的default部分
需要注意的是,每个case代码块内部的break语句不能少,否则会接下去执行下一个case代码块,而不是跳出switch结构
1 | |
case代码块之中没有break语句,导致不会跳出switch结构,而会一直执行下去
1 | |
switch语句部分和case语句部分,都可以使用表达式。
1 | |
上面代码的default部分,是永远不会执行到的。
三元运算符 ?:
JavaScript 还有一个三元运算符(即该运算符需要三个运算子)?:,也可以用于逻辑判断
(条件) ? 表达式1 : 表达式2
上面代码中,如果“条件”为true,则返回“表达式1”的值,否则返回“表达式2”的值
1 | |
上面代码中,如果n可以被2整除,则even等于true,否则等于false 它等同于下面的形式
1 | |
这个三元运算符可以被视为if...else...的简写形式,因此可以用于多种场合
1 | |
上面代码利用三元运算符,输出相应的提示
1 | |
上面代码利用三元运算符,在字符串之中插入不同的值
循环语句
循环语句用于重复执行某个操作,它有多种形式
while 循环
While语句包括一个循环条件和一段代码块,只要条件为真,就不断循环执行代码块
1 | |
1 | |
while语句的循环条件是一个表达式,必须放在圆括号中
代码块部分,如果只有一条语句,可以省略大括号,否则就必须加上大括号
1 | |
上面的代码将循环100次,直到i等于100为止。
下面的例子是一个无限循环,因为循环条件总是为真。
1 | |
for 循环
for语句是循环命令的另一种形式,可以指定循环的起点、终点和终止条件。
1 | |
1 | |
for语句后面的括号里面,有三个表达式
初始化表达式(initialize):确定循环变量的初始值,只在循环开始时执行一次
条件表达式(test):每轮循环开始时,都要执行这个条件表达式,只有值为真,才继续进行循环
递增表达式(increment):每轮循环的最后一个操作,通常用来递增循环变量
1 | |
上面代码中,初始化表达式是var i = 0,即初始化一个变量i;
测试表达式是i < x,即只要i小于x,就会执行循环;
递增表达式是i++,即每次循环结束后,i增大1
忽略成分
for语句的三个部分(initialize、test、increment),可以省略任何一个,也可以全部省略
1 | |
上面代码省略了for语句表达式的三个部分,结果就导致了一个无限循环
do…while 循环
do...while循环与while循环类似,唯一的区别就是先运行一次循环体,然后判断循环条件
1 | |
1 | |
不管条件是否为真,do...while循环至少运行一次,这是这种结构最大的特点
注意不要省略
while语句后面的分号
1 | |
break 语句和 continue 语句
break语句和continue语句都具有跳转作用,可以让代码不按既有的顺序执行
break语句用于跳出代码块或循环
1 | |
上面代码只会执行10次循环,一旦i等于10,就会跳出循环。
continue语句用于立即终止本轮循环,返回循环结构的头部,开始下一轮循环。
1 | |
上面代码只有在i为奇数时,才会输出i的值。如果i为偶数,则直接进入下一轮循环
如果存在多重循环,不带参数的break语句和continue语句都只针对最内层循环
标签 Label
(不建议使用)JavaScript 语言允许,语句的前面有标签(label),相当于定位符,用于跳转到程序的任意位置
1 | |
标签可以是任意的标识符,但不能是保留字,语句部分可以是任意语句
标签通常与break语句和continue语句配合使用,跳出特定的循环。
1 | |
上面代码为一个双重循环区块,break命令后面加上了top标签(注意,top不用加引号),满足条件时,直接跳出双层循环
如果break语句后面不使用标签,则只能跳出内层循环,进入下一次的外层循环
标签也可以用于跳出代码块
1 | |
上面代码执行到break foo,就会跳出区块。
数据类型
类型测定
JavaScript 有三种方法,可以确定一个值到底是什么类型
typeof运算符instanceof运算符Object.prototype.toString方法
instanceof运算符 和 Object.prototype.toString方法,将在后文介绍。这里介绍 typeof运算符
typeof运算符可以返回一个值的数据类型
1 | |
注意:typeof null 返回的是 “object”
null 和 undefined
null与undefined都可以表示“没有”,含义非常相似
将一个变量赋值为undefined或null,语法效果几乎没区别
1 | |
上面代码中,变量a分别被赋值为undefined和null,这两种写法的效果几乎等价
在if语句中,它们都会被自动转为false,相等运算符(==)甚至直接报告两者相等
1 | |
从上面代码可见,两者的行为是何等相似!
谷歌公司开发的 JavaScript 语言的替代品 Dart 语言,就明确规定只有null,没有undefined
既然含义与用法都差不多,为什么要同时设置两个这样的值,这不是无端增加复杂度,令初学者困扰吗?这与历史原因有关
历史原因
1995年JavaScript诞生时,最初像Java一样,只设置了null表示”无”。根据C语言的传统,null可以自动转为0
但是,JavaScript的设计者 Brendan Eich,觉得这样做还不够
首先,第一版的JavaScript里面,null就像在Java里一样,被当成一个对象,Brendan Eich 觉得表示“无”的值最好不是对象
其次,那时的JavaScript不包括错误处理机制,Brendan Eich 觉得,如果null自动转为0,很不容易发现错误
因此,他又设计了一个undefined。区别是这样的:null是一个表示“空”的对象,转为数值时为0;undefined是一个表示”此处无定义”的原始值,转为数值时为NaN
对于null和undefined,大致可以像下面这样理解
null表示空值,即该处的值现在为空。调用函数时,某个参数未设置任何值,这时就可以传入null,表示该参数为空
undefined表示“未定义”,下面是返回undefined的典型场景
1 | |
Boolean 布尔值
布尔值代表“真”和“假”两个状态
“真”用关键字true表示,“假”用关键字false表示。布尔值只有这两个值
进行逻辑运算会得到布尔值
- 前置逻辑运算符:
!(Not) - 相等运算符:
===,!==,==,!= - 比较运算符:
>,>=,<,<=
如果JavaScript预期某个位置应该是布尔值,会将该位置上现有的值自动转为布尔值
转换规则
转换规则是除了下面六个值被转为false,其他值都视为trueundefined、null、false、0、NaN、""(空字符串)、''(空字符串)、[](空数组)、{}(空对象)
布尔值往往用于程序流程的控制
1 | |
上面代码中,if命令后面的判断条件,预期应该是一个布尔值,所以 JavaScript 自动将空字符串,转为布尔值false,导致程序不会进入代码块,所以没有任何输出
Number 数值
只有浮点数
JavaScript 内部,所有数字都是以64位浮点数形式储存,即使整数也是如此。所以,1与1.0是相同的,是同一个数
1 | |
这就是说,JavaScript 语言的底层根本没有整数,所有数字都是小数(64位浮点数)。容易造成混淆的是,某些运算只有整数才能完成,此时 JavaScript 会自动把64位浮点数,转成32位整数,然后再进行运算
1 | |
数值精度
JavaScript 浮点数的64个二进制位,从最左边开始,是这样组成的。
- 第1位:符号位,0表示正数,1表示负数
- 第2位到第12位(共11位):指数部分
- 第13位到第64位(共52位):小数部分(即有效数字)
符号位决定了一个数的正负,指数部分决定了数值的大小,小数部分决定了数值的精度
精度最多只能到53个二进制位,这意味着,绝对值小于2的53次方的整数,即 -2^53 到 2^53,都可以精确表示
1 | |
上面代码中,大于2的53次方以后,整数运算的结果开始出现错误。所以,大于2的53次方的数值,都无法保持精度。由于2的53次方是一个16位的十进制数值,所以简单的法则就是,JavaScript 对15位的十进制数都可以精确处理
数值范围
64位浮点数的指数部分的长度是11个二进制位,意味着指数部分的最大值是2047(2的11次方减1)。也就是说,64位浮点数的指数部分的值最大为2047,分出一半表示负数,则 JavaScript 能够表示的数值范围为2^1024到2^-1023(开区间),超出这个范围的数无法表示
如果一个数大于等于2的1024次方,那么就会发生“正向溢出”,即 JavaScript 无法表示这么大的数,这时就会返回Infinity
1 | |
如果一个数小于等于2的-1075次方(指数部分最小值-1023,再加上小数部分的52位),那么就会发生为“负向溢出”,即 JavaScript 无法表示这么小的数,这时会直接返回0
1 | |
JavaScript 提供Number对象的MAX_VALUE和MIN_VALUE属性,返回可以表示的具体的最大值和最小值
1 | |
表示方法
JavaScript 的数值有多种表示方法,可以用字面形式直接表示,比如35(十进制)和0xFF(十六进制)
1 | |
科学计数法允许字母e或E的后面,跟着一个整数,表示这个数值的指数部分
以下两种情况,JavaScript 会自动将数值转为科学计数法表示,其他情况都采用字面形式直接表示
小数点前的数字多于21位
1
2
3
4
51234567890123456789012
// 1.2345678901234568e+21
123456789012345678901
// 123456789012345680000小数点后的零多于5个
1
2
3
4
5
6// 小数点后紧跟5个以上的零,
// 就自动转为科学计数法
0.0000003 // 3e-7
// 否则,就保持原来的字面形式
0.000003 // 0.000003
进制
使用字面量(Literal)直接表示一个数值时,JavaScript 对整数提供四种进制的表示方法:
- 十进制:没有前导0的数值
- 八进制:有前缀0o或0O的数值,或者有前导0、且只用到0-7的八个阿拉伯数字的数值
- 十六进制:有前缀0x或0X的数值
- 二进制:有前缀0b或0B的数值
默认情况下,JavaScript 内部会自动将八进制、十六进制、二进制转为十进制
1 | |
如果八进制、十六进制、二进制的数值里面,出现不属于该进制的数字,就会报错
1 | |
通常来说,有前导0的数值会被视为八进制,但是如果前导0后面有数字8和9,则该数值被视为十进制
1 | |
前导0表示八进制,处理时很容易造成混乱。ES5 的严格模式和 ES6,已经废除了这种表示法,但是浏览器为了兼容以前的代码,目前还继续支持这种表示法
特殊数值
正零和负零
JavaScript 内部实际上存在2个0:一个是+0,一个是-0
区别就是64位浮点数表示法的符号位不同。它们是等价的
1 | |
几乎所有场合,正零和负零都会被当作正常的0
1 | |
唯一有区别的场合是,+0或-0当作分母,返回的值是不相等的
1 | |
上面的代码之所以出现这样结果,是因为除以正零得到+Infinity,除以负零得到-Infinity,这两者是不相等的
NaN
NaN是 JavaScript 的特殊值,表示“非数字”(Not a Number),主要出现在将字符串解析成数字出错的场合
1 | |
上面代码运行时,会自动将字符串x转为数值,但是由于x不是数值,所以最后得到结果为NaN,表示它是“非数字”
另外,一些数学函数的运算结果会出现NaN
1 | |
0除以0也会得到NaN
1 | |
需要注意的是,NaN不是独立的数据类型,而是一个特殊数值,它的数据类型依然属于Number,使用typeof运算符可以看得很清楚
1 | |
NaN不等于任何值,包括它本身
1 | |
数组的indexOf方法内部使用的是严格相等运算符,所以该方法对NaN不成立
1 | |
NaN在布尔运算时被当作false
1 | |
NaN与任何数(包括它自己)的运算,得到的都是NaN
1 | |
Infinity
Infinity表示“无穷”,用来表示两种场景
- 一个正的数值太大,或一个负的数值太小,无法表示
- 另一种是非0数值除以0,得到Infinity 上面代码中,第一个场景是一个表达式的计算结果太大,超出了能够表示的范围,因此返回
1
2
3
4
5
6
7// 场景一
Math.pow(2, 1024)
// Infinity
// 场景二
0 / 0 // NaN
1 / 0 // InfinityInfinity。第二个场景是0除以0会得到NaN,而非0数值除以0,会返回Infinity
Infinity有正负之分,Infinity表示正的无穷,-Infinity表示负的无穷
1 | |
由于数值正向溢出(overflow)、负向溢出(underflow)和被0除,JavaScript 都不报错,所以单纯的数学运算几乎没有可能抛出错误
Infinity大于一切数值(除了NaN),-Infinity小于一切数值(除了NaN)
1 | |
Infinity与NaN比较,总是返回false
1 | |
Infinity的四则运算,符合无穷的数学计算规则
1 | |
常用全局方法
parseInt()
用于将字符串转为整数
1 | |
如果字符串头部有空格,空格会被自动去除
1 | |
如果parseInt的参数不是字符串,则会先转为字符串再转换
1 | |
字符串转为整数的时候,是一个个字符依次转换
如果遇到不能转为数字的字符,就不再进行下去,返回已经转好的部分
1 | |
如果字符串的第一个字符不能转化为数字(后面跟着数字的正负号除外),返回NaN。
1 | |
如果字符串以0x或0X开头,parseInt会将其按照十六进制数解析
如果字符串以0开头,将其按照10进制解析
1 | |
对于那些会自动转为科学计数法的数字,parseInt会将科学计数法的表示方法视为字符串,因此导致一些奇怪的结果
1 | |
parseInt方法还可以接受第二个参数(2到36之间),表示被解析的值的进制,返回该值对应的十进制数
默认情况下,parseInt的第二个参数为10,即默认是十进制转十进制
1 | |
如果第二个参数不是数值,会被自动转为一个整数
这个整数只有在2到36之间,才能得到有意义的结果,超出这个范围,则返回NaN
如果第二个参数是0、undefined和null,则直接忽略
1 | |
如果字符串包含对于指定进制无意义的字符,则从最高位开始,只返回可以转换的数值
如果最高位无法转换,则直接返回NaN
1 | |
对于二进制来说,1是有意义的字符,而5、4、6都是无意义的字符,所以第一行返回1,第二行返回NaN
前面说过,如果parseInt的第一个参数不是字符串,会被先转为字符串。这会导致一些令人意外的结果
1 | |
上面代码中,十六进制的0x11会被先转为十进制的17,再转为字符串。然后,再用36进制或二进制解读字符串17,最后返回结果43和1
这种处理方式,对于八进制的前缀0,尤其需要注意。
1 | |
上面代码中,第一行的011会被先转为字符串9,因为9不是二进制的有效字符,所以返回NaN。如果直接计算parseInt('011', 2),011则是会被当作二进制处理,返回3
JavaScript 不再允许将带有前缀0的数字视为八进制数,而是要求忽略这个0。但是,为了保证兼容性,大部分浏览器并没有部署这一条规定
parseFloat()
parseFloat方法用于将一个字符串转为浮点数。
1 | |
如果字符串符合科学计数法,则会进行相应的转换
1 | |
如果字符串包含不能转为浮点数的字符,则不再进行往后转换,返回已经转好的部分
1 | |
parseFloat方法会自动过滤字符串前导的空格。
1 | |
如果参数不是字符串,或者字符串的第一个字符不能转化为浮点数,则返回NaN
1 | |
上面代码中,尤其值得注意,parseFloat会将空字符串转为NaN
这些特点使得parseFloat的转换结果不同于Number函数
1 | |
isNaN()
isNaN方法可以用来判断一个值是否为NaN
1 | |
但是,isNaN只对数值有效,如果传入其他值,会被先转成数值
比如,传入字符串的时候,字符串会被先转成NaN,所以最后返回true,这一点要特别引起注意。也就是说,isNaN为true的值,有可能不是NaN,而是一个字符串
1 | |
出于同样的原因,对于对象和数组,isNaN也返回true
1 | |
但是,对于空数组和只有一个数值成员的数组,isNaN返回false
1 | |
上面代码之所以返回false,原因是这些数组能被Number函数转成数值
因此,使用isNaN之前,最好判断一下数据类型。
1 | |
判断NaN更可靠的方法是,利用NaN为唯一不等于自身的值的这个特点,进行判断。
1 | |
isFinite()
isFinite方法返回一个布尔值,表示某个值是否为正常的数值
1 | |
除了Infinity、-Infinity、NaN和undefined这几个值会返回false,isFinite对于其他的数值都会返回true
String 字符串
字符串就是零个或多个排在一起的字符,放在单引号或双引号之中
1 | |
单引号字符串的内部,可以使用双引号。双引号字符串的内部,可以使用单引号
1 | |
如果要在单引号字符串的内部,使用单引号,就必须在内部的单引号前面加上反斜杠,用来转义。双引号字符串内部使用双引号,也是如此
1 | |
由于 HTML 语言的属性值使用双引号,所以很多项目约定 JavaScript 语言的字符串只使用单引号,默认应该遵守这个约定
字符串默认只能写在一行内,分成多行将会报错
1 | |
如果长字符串必须分成多行,可以在每一行的尾部使用反斜杠
1 | |
上面代码表示,加了反斜杠以后,原来写在一行的字符串,可以分成多行书写。但是,输出的时候还是单行,效果与写在同一行完全一样。注意,反斜杠的后面必须是换行符,而不能有其他字符(比如空格),否则会报错
连接运算符(+)可以连接多个单行字符串,将长字符串拆成多行书写,输出的时候也是单行
1 | |
如果想输出多行字符串,有一种利用多行注释的变通方法
1 | |
上面的例子中,输出的字符串就是多行
转义
反斜杠(\)在字符串内有特殊含义,用来表示一些特殊字符,所以又称为转义符
需要用反斜杠转义的特殊字符,主要有下面这些
- \0 :null(\u0000)
- \b :后退键(\u0008)
- \f :换页符(\u000C)
- \n :换行符(\u000A)
- \r :回车键(\u000D)
- \t :制表符(\u0009)
- \v :垂直制表符(\u000B)
- ' :单引号(\u0027)
- " :双引号(\u0022)
- \ :反斜杠(\u005C)
反斜杠还有三种特殊用法。
\HHH
反斜杠后面紧跟三个八进制数(000到377),代表一个字符
HHH对应该字符的Unicode码点,比如\251表示版权符号
显然,这种方法只能输出256种字符\xHH
\x后面紧跟两个十六进制数(00到FF),代表一个字符
HH对应该字符的 Unicode 码点,比如\xA9表示版权符号
这种方法也只能输出256种字符\uXXXX
\u后面紧跟四个十六进制数(0000到FFFF),代表一个字符
XXXX对应该字符的Unicode码点,比如\u00A9表示版权符号
下面是这三种字符特殊写法的例子。
1 | |
如果在非特殊字符前面使用反斜杠,则反斜杠会被省略。
1 | |
上面代码中,a是一个正常字符,前面加反斜杠没有特殊含义,反斜杠会被自动省略
字符串与数组
字符串可以被视为字符数组,因此可以使用数组的方括号运算符,用来返回某个位置的字符(位置编号从0开始)
1 | |
如果方括号中的数字超过字符串的长度,或者方括号中根本不是数字,则返回undefined
1 | |
但是,字符串与数组的相似性仅此而已。实际上,无法改变字符串之中的单个字符
1 | |
length 属性
length属性返回字符串的长度,该属性也是无法改变的
1 | |
字符集
JavaScript 使用 Unicode 字符集JavaScript 引擎内部,所有字符都用 Unicode 表示
JavaScript 不仅以 Unicode 储存字符,还允许直接在程序中使用 Unicode 码点表示字符,即将字符写成 \uxxxx 的形式,其中xxxx代表该字符的 Unicode 码点
1 | |
解析代码的时候,JavaScript 会自动识别一个字符是字面形式表示,还是 Unicode 形式表示
输出给用户的时候,所有字符都会转成字面形式
1 | |
每个字符在 JavaScript 内部都是以16位(即2个字节)的 UTF-16 格式储存JavaScript 的单位字符长度固定为16位长度,即2个字节
但是,UTF-16 有两种长度:对于码点在 U+0000 到 U+FFFF 之间的字符,长度为16位(即2个字节);对于码点在U+10000到U+10FFFF之间的字符,长度为32位(即4个字节),而且前两个字节在 0xD800 到 0xDBFF 之间,后两个字节在 0xDC00 到 0xDFFF 之间
举例来说,码点 U+1D306 对应的字符为 𝌆,它写成 UTF-16 就是 0xD834 0xDF06
JavaScript 对 UTF-16 的支持是不完整的,由于历史原因,只支持两字节的字符,不支持四字节的字符
这是因为 JavaScript 第一版发布的时候,Unicode 的码点只编到 U+FFFF,因此两字节足够表示了。后来,Unicode 纳入的字符越来越多,出现了四字节的编码。但是,JavaScript 的标准此时已经定型了,统一将字符长度限制在两字节,导致无法识别四字节的字符。上一节的那个四字节字符𝌆,浏览器会正确识别这是一个字符,但是 JavaScript 无法识别,会认为这是两个字符
1 | |
上面代码中,JavaScript 认为𝌆的长度为2,而不是1
对于码点在 U+10000 到 U+10FFFF 之间的字符,JavaScript 总是认为它们是两个字符(length属性为2)。所以处理的时候,必须把这一点考虑在内,也就是说,JavaScript 返回的字符串长度可能是不正确的
Base64 转码
有时,文本里面包含一些不可打印的符号,比如 ASCII 码0到31的符号都无法打印出来,这时可以使用 Base64 编码,将它们转成可以打印的字符
另一个场景是,有时需要以文本格式传递二进制数据,那么也可以使用 Base64 编码
所谓 Base64 就是一种编码方法,可以将任意值转成 0~9、A~Z、a-z、+和/这64个字符组成的可打印字符
使用它的主要目的,不是为了加密,而是为了不出现特殊字符,简化程序的处理
JavaScript 原生提供两个 Base64 相关的方法
- btoa():任意值转为 Base64 编码
- atob():Base64 编码转为原来的值
1 | |
注意,这两个方法不适合非 ASCII 码的字符,会报错
1 | |
要将非 ASCII 码字符转为 Base64 编码,必须中间插入一个转码环节,再使用这两个方法
1 | |
Object 对象
生成方法
对象(object)是 JavaScript 语言的核心概念,也是最重要的数据类型
什么是对象?简单说,对象就是一组“键值对”(key-value)的集合,是一种无序的复合数据集合。
1 | |
上面代码中,大括号就定义了一个对象,它被赋值给变量obj,所以变量obj就指向一个对象
该对象内部包含两个键值对(又称为两个“成员”),第一个键值对是foo: 'Hello',其中foo是“键名”(成员的名称),字符串Hello是“键值”(成员的值)
键名与键值之间用冒号分隔。第二个键值对是bar: 'World',bar是键名,World是键值。两个键值对之间用逗号分隔
键名
对象的所有键名都是字符串(ES6 又引入了 Symbol 值也可以作为键名),所以加不加引号都可以。上面的代码也可以写成下面这样
1 | |
如果键名是数值,会被自动转为字符串
1 | |
上面代码中,对象obj的所有键名虽然看上去像数值,实际上都被自动转成了字符串。
如果键名不符合标识名的条件(比如第一个字符为数字,或者含有空格或运算符),且也不是数字,则必须加上引号,否则会报错
1 | |
对象的每一个键名又称为“属性”(property),它的“键值”可以是任何数据类型
如果一个属性的值为函数,通常把这个属性称为“方法”,它可以像函数那样调用
1 | |
如果属性的值还是一个对象,就形成了链式引用
1 | |
上面代码中,对象o1的属性foo指向对象o2,就可以链式引用o2的属性。
对象的属性之间用逗号分隔,最后一个属性后面可以加逗号(trailing comma),也可以不加
1 | |
属性可以动态创建,不必在对象声明时就指定
1 | |
对象的引用
如果不同的变量名指向同一个对象,那么它们都是这个对象的引用,也就是说指向同一个内存地址
修改其中一个变量,会影响到其他所有变量
1 | |
上面代码中,o1和o2指向同一个对象,因此为其中任何一个变量添加属性,另一个变量都可以读写该属性
此时,如果取消某一个变量对于原对象的引用,不会影响到另一个变量
1 | |
上面代码中,o1和o2指向同一个对象,然后o1的值变为1,这时不会对o2产生影响,o2还是指向原来的那个对象
但是,这种引用只局限于对象,如果两个变量指向同一个原始类型的值。那么,变量这时都是值的拷贝
1 | |
上面的代码中,当x的值发生变化后,y的值并不变,这就表示y和x并不是指向同一个内存地址
表达式还是语句?
对象采用大括号表示,这导致了一个问题:如果行首是一个大括号,它到底是表达式还是语句?
1 | |
JavaScript 引擎读到上面这行代码,会发现可能有两种含义
第一种可能是,这是一个表达式,表示一个包含foo属性的对象;
第二种可能是,这是一个语句,表示一个代码区块,里面有一个标签foo,指向表达式123
为了避免这种歧义,JavaScript 引擎的做法是,如果遇到这种情况,无法确定是对象还是代码块,一律解释为代码块
1 | |
上面的语句是一个代码块,而且只有解释为代码块,才能执行
如果要解释为对象,最好在大括号前加上圆括号。因为圆括号的里面,只能是表达式,所以确保大括号只能解释为对象
1 | |
这种差异在eval语句(作用是对字符串求值)中反映得最明显
1 | |
上面代码中,如果没有圆括号,eval将其理解为一个代码块;加上圆括号以后,就理解成一个对象
属性的操作
属性的读取
读取对象的属性,有两种方法,一种是使用点运算符,还有一种是使用方括号运算符
1 | |
上面代码分别采用点运算符和方括号运算符,读取属性p。
请注意,如果使用方括号运算符,键名必须放在引号里面,否则会被当作变量处理
1 | |
上面代码中,引用对象obj的foo属性时,如果使用点运算符,foo就是字符串;
如果使用方括号运算符,但是不使用引号,那么foo就是一个变量,指向字符串bar
方括号运算符内部还可以使用表达式
1 | |
数字键可以不加引号,因为会自动转成字符串
1 | |
上面代码中,对象obj的数字键0.7,加不加引号都可以,因为会被自动转为字符串
注意,数值键名不能使用点运算符(因为会被当成小数点),只能使用方括号运算符
1 | |
上面代码的第一个表达式,对数值键名123使用点运算符,结果报错
第二个表达式使用方括号运算符,结果就是正确的
属性的赋值
点运算符和方括号运算符,不仅可以用来读取值,还可以用来赋值
1 | |
上面代码中,分别使用点运算符和方括号运算符,对属性赋值
JavaScript 允许属性的“后绑定”,也就是说,你可以在任意时刻新增属性,没必要在定义对象的时候,就定义好属性
1 | |
属性的查看
查看一个对象本身的所有属性,可以使用Object.keys方法
1 | |
属性的删除:delete 命令
delete命令用于删除对象的属性,删除成功后返回true
1 | |
上面代码中,delete命令删除对象obj的p属性。删除后,再读取p属性就会返回undefined,而且Object.keys方法的返回值也不再包括该属性
注意,删除一个不存在的属性,delete不报错,而且返回true
1 | |
上面代码中,对象obj并没有p属性,但是delete命令照样返回true
因此,不能根据delete命令的结果,认定某个属性是存在的
只有一种情况,delete命令会返回false,那就是该属性存在,且不得删除
1 | |
上面代码之中,对象obj的p属性是不能删除的,所以delete命令返回false
另外,需要注意的是,delete命令只能删除对象本身的属性,无法删除继承的属性
1 | |
上面代码中,toString是对象obj继承的属性,虽然delete命令返回true,但该属性并没有被删除,依然存在
这个例子还说明,即使delete返回true,该属性依然可能读取到值
属性是否存在:in 运算符
in运算符用于检查对象是否包含某个属性(注意,检查的是键名,不是键值),如果包含就返回true,否则返回false
它的左边是一个字符串,表示属性名,右边是一个对象
1 | |
in运算符的一个问题是,它不能识别哪些属性是对象自身的,哪些属性是继承的。就像上面代码中,对象obj本身并没有toString属性,但是in运算符会返回true,因为这个属性是继承的
这时,可以使用对象的hasOwnProperty方法判断一下,是否为对象自身的属性
1 | |
属性的遍历:for…in 循环
for...in循环用来遍历一个对象的全部属性
1 | |
for...in循环有两个使用注意点。
- 它遍历的是对象所有可遍历(enumerable)的属性,会跳过不可遍历的属性。
- 它不仅遍历对象自身的属性,还遍历继承的属性。
举例来说,对象都继承了toString属性,但是for...in循环不会遍历到这个属性
1 | |
上面代码中,对象obj继承了toString属性,该属性不会被for...in循环遍历到,因为它默认是“不可遍历”的
如果继承的属性是可遍历的,那么就会被for...in循环遍历到
但是,一般情况下,都是只想遍历对象自身的属性,所以使用for...in的时候,应该结合使用hasOwnProperty方法,在循环内部判断一下,某个属性是否为对象自身的属性
1 | |
with 语句
不建议使用
with语句的格式如下:
1 | |
它的作用是操作同一个对象的多个属性时,提供一些书写的方便
1 | |
注意,如果with区块内部有变量的赋值操作,必须是当前对象已经存在的属性,否则会创造一个当前作用域的全局变量
1 | |
上面代码中,对象obj并没有p1属性,对p1赋值等于创造了一个全局变量p1
正确的写法应该是,先定义对象obj的属性p1,然后在with区块内操作它
这是因为with区块没有改变作用域,它的内部依然是当前作用域
这造成了with语句的一个很大的弊病,就是绑定对象不明确
1 | |
单纯从上面的代码块,根本无法判断x到底是全局变量,还是对象obj的一个属性
这非常不利于代码的除错和模块化,编译器也无法对这段代码进行优化,只能留到运行时判断,这就拖慢了运行速度
因此,建议不要使用with语句,可以考虑用一个临时变量代替with
1 | |
Function 函数
函数是一段可以反复调用的代码块。函数还能接受输入的参数,不同的参数会返回不同的值
概述
函数的声明
(1)function 命令
function命令声明的代码区块,就是一个函数function命令后面是函数名,函数名后面是一对圆括号,里面是传入函数的参数。函数体放在大括号里面
1 | |
上面的代码命名了一个print函数,以后使用print()这种形式,就可以调用相应的代码。这叫做函数的声明(Function Declaration)
(2)函数表达式
除了用function命令声明函数,还可以采用变量赋值的写法
1 | |
这种写法将一个匿名函数赋值给变量
这时,这个匿名函数又称函数表达式(Function Expression),因为赋值语句的等号右侧只能放表达式
采用函数表达式声明函数时,function命令后面不带有函数名
如果加上函数名,该函数名只在函数体内部有效,在函数体外部无效
1 | |
上面代码在函数表达式中,加入了函数名x。这个x只在函数体内部可用,指代函数表达式本身,其他地方都不可用
这种写法的用处有两个,一是可以在函数体内部调用自身,二是方便除错(除错工具显示函数调用栈时,将显示函数名,而不再显示这里是一个匿名函数)
1 | |
需要注意的是,函数的表达式需要在语句的结尾加上分号,表示语句结束
而函数的声明在结尾的大括号后面不用加分号
总的来说,这两种声明函数的方式,差别很细微,可以近似认为是等价的
(3)Function 构造函数
1 | |
上面代码中,Function构造函数接受三个参数,除了最后一个参数是add函数的“函数体”,其他参数都是add函数的参数
你可以传递任意数量的参数给Function构造函数,只有最后一个参数会被当做函数体,如果只有一个参数,该参数就是函数体
1 | |
Function构造函数可以不使用new命令,返回结果完全一样
总的来说,这种声明函数的方式非常不直观,几乎无人使用
函数的重复声明
如果同一个函数被多次声明,后面的声明就会覆盖前面的声明
1 | |
上面代码中,后一次的函数声明覆盖了前面一次
而且,由于函数名的提升,前一次声明在任何时候都是无效的,这一点要特别注意
圆括号运算符,return 语句和递归
调用函数时,要使用圆括号运算符。圆括号之中,可以加入函数的参数
1 | |
上面代码中,函数名后面紧跟一对圆括号,就会调用这个函数
函数体内部的return语句,表示返回。JavaScript 引擎遇到return语句,就直接返回return后面的那个表达式的值,后面即使还有语句,也不会得到执行
也就是说,return语句所带的那个表达式,就是函数的返回值。return语句不是必需的,如果没有的话,该函数就不返回任何值,或者说返回undefined
函数可以调用自身,这就是递归(recursion)
下面就是通过递归,计算斐波那契数列的代码
1 | |
上面代码中,fib函数内部又调用了fib,计算得到斐波那契数列的第6个元素是8
第一等公民
JavaScript 语言将函数看作一种值,与其它值(数值、字符串、布尔值等等)地位相同
凡是可以使用值的地方,就能使用函数
比如,可以把函数赋值给变量和对象的属性,也可以当作参数传入其他函数,或者作为函数的结果返回
函数只是一个可以执行的值,此外并无特殊之处
由于函数与其他数据类型地位平等,所以在 JavaScript 语言中又称函数为第一等公民
1 | |
函数名的提升
JavaScript 引擎将函数名视同变量名,所以采用function命令声明函数时,整个函数会像变量声明一样,被提升到代码头部
所以,下面的代码不会报错
1 | |
表面上,上面代码好像在声明之前就调用了函数f
但是实际上,由于“变量提升”,函数f被提升到了代码头部,也就是在调用之前已经声明了 但是,如果采用赋值语句定义函数,JavaScript 就会报错
1 | |
上面的代码等同于下面的形式
1 | |
上面代码第二行,调用f的时候,f只是被声明了,还没有被赋值,等于undefined,所以会报错
注意,如果像下面例子那样,采用function命令和var赋值语句声明同一个函数,由于存在函数提升,最后会采用var赋值语句的定义
1 | |
上面例子中,表面上后面声明的函数f,应该覆盖前面的var赋值语句,但是由于存在函数提升,实际上正好反过来
函数的属性和方法
name 属性
函数的name属性返回函数的名字
1 | |
如果是通过变量赋值定义的函数,那么name属性返回变量名
1 | |
但是,上面这种情况,只有在变量的值是一个匿名函数时才是如此
如果变量的值是一个具名函数,那么name属性返回function关键字之后的那个函数名
1 | |
上面代码中,f3.name返回函数表达式的名字。注意,真正的函数名还是f3,而myName这个名字只在函数体内部可用
name属性的一个用处,就是获取参数函数的名字
1 | |
上面代码中,函数test内部通过name属性,就可以知道传入的参数是什么函数
length 属性
函数的length属性返回函数预期传入的参数个数,即函数定义之中的参数个数
1 | |
上面代码定义了空函数f,它的length属性就是定义时的参数个数
不管调用时输入了多少个参数,length属性始终等于2
length属性提供了一种机制,判断定义时和调用时参数的差异,以便实现面向对象编程的“方法重载”(overload)
toString()
函数的toString()方法返回一个字符串,内容是函数的源码
1 | |
上面示例中,函数f的toString()方法返回了f的源码,包含换行符在内
对于那些原生的函数,toString()方法返回function (){[native code]}
1 | |
上面代码中,Math.sqrt()是 JavaScript 引擎提供的原生函数,toString()方法就返回原生代码的提示
函数内部的注释也可以返回
1 | |
利用这一点,可以变相实现多行字符串
1 | |
上面示例中,函数f内部有一个多行注释,toString()方法拿到f的源码后,去掉首尾两行,就得到了一个多行字符串
函数作用域
定义
作用域(scope)指的是变量存在的范围。在 ES5 的规范中,JavaScript 只有两种作用域:
一种是全局作用域,变量在整个程序中一直存在,所有地方都可以读取
另一种是函数作用域,变量只在函数内部存在。ES6 又新增了块级作用域,本教程不涉及
对于顶层函数来说,函数外部声明的变量就是全局变量(global variable),它可以在函数内部读取
1 | |
上面的代码表明,函数f内部可以读取全局变量v
在函数内部定义的变量,外部无法读取,称为“局部变量”(local variable)
1 | |
上面代码中,变量v在函数内部定义,所以是一个局部变量,函数之外就无法读取
函数内部定义的变量,会在该作用域内覆盖同名全局变量
1 | |
上面代码中,变量v同时在函数的外部和内部有定义
结果,在函数内部定义,局部变量v覆盖了全局变量v
注意,对于var命令来说,局部变量只能在函数内部声明,在其他区块中声明,一律都是全局变量
1 | |
上面代码中,变量x在条件判断区块之中声明,结果就是一个全局变量,可以在区块之外读取
函数内部的变量提升
与全局作用域一样,函数作用域内部也会产生“变量提升”现象var命令声明的变量,不管在什么位置,变量声明都会被提升到函数体的头部
1 | |
函数本身的作用域
函数本身也是一个值,也有自己的作用域
它的作用域与变量一样,就是其声明时所在的作用域,与其运行时所在的作用域无关
1 | |
上面代码中,函数x是在函数f的外部声明的,所以它的作用域绑定外层,内部变量a不会到函数f体内取值,所以输出1,而不是2
总之,函数执行时所在的作用域,是定义时的作用域,而不是调用时所在的作用域
很容易犯错的一点是,如果函数A调用函数B,却没考虑到函数B不会引用函数A的内部变量
1 | |
上面代码将函数x作为参数,传入函数y
但是,函数x是在函数y体外声明的,作用域绑定外层,因此找不到函数y的内部变量a,导致报错。
同样的,函数体内部声明的函数,作用域绑定函数体内部。
1 | |
上面代码中,函数foo内部声明了一个函数bar,bar的作用域绑定foo
当我们在foo外部取出bar执行时,变量x指向的是foo内部的x,而不是foo外部的x
正是这种机制,构成了下文要讲解的“闭包”现象
参数
概述
函数运行的时候,有时需要提供外部数据,不同的外部数据会得到不同的结果,这种外部数据就叫参数
1 | |
上式的x就是square函数的参数
每次运行的时候,需要提供这个值,否则得不到结果
参数的省略
函数参数不是必需的,JavaScript 允许省略参数
1 | |
上面代码的函数f定义了两个参数,但是运行时无论提供多少个参数(或者不提供参数),JavaScript 都不会报错
省略的参数的值就变为undefined
需要注意的是,函数的length属性与实际传入的参数个数无关,只反映函数预期传入的参数个数
但是,没有办法只省略靠前的参数,而保留靠后的参数
如果一定要省略靠前的参数,只有显式传入undefined
1 | |
上面代码中,如果省略第一个参数,就会报错
传递方式
函数参数如果是原始类型的值(数值、字符串、布尔值),传递方式是传值传递(passes by value)
这意味着,在函数体内修改参数值,不会影响到函数外部
1 | |
上面代码中,变量p是一个原始类型的值,传入函数f的方式是传值传递
因此,在函数内部,p的值是原始值的拷贝,无论怎么修改,都不会影响到原始值
但是,如果函数参数是复合类型的值(数组、对象、其他函数),传递方式是传址传递(pass by reference)
也就是说,传入函数的原始值的地址,因此在函数内部修改参数,将会影响到原始值
1 | |
上面代码中,传入函数f的是参数对象obj的地址
因此,在函数内部修改obj的属性p,会影响到原始值
注意,如果函数内部修改的,不是参数对象的某个属性,而是替换掉整个参数,这时不会影响到原始值
1 | |
上面代码中,在函数f()内部,参数对象obj被整个替换成另一个值
这时不会影响到原始值。这是因为,形式参数(o)的值实际是参数obj的地址,重新对o赋值导致o指向另一个地址,保存在原地址上的值当然不受影响
同名参数
如果有同名的参数,则取最后出现的那个值
1 | |
上面代码中,函数f()有两个参数,且参数名都是a
取值的时候,以后面的a为准,即使后面的a没有值或被省略,也是以其为准
1 | |
调用函数f()的时候,没有提供第二个参数,a的取值就变成了undefined
这时,如果要获得第一个a的值,可以使用arguments对象
1 | |
arguments 对象
(1)定义
由于 JavaScript 允许函数有不定数目的参数,所以需要一种机制,可以在函数体内部读取所有参数。这就是arguments对象的由来
arguments对象包含了函数运行时的所有参数,arguments[0]就是第一个参数,arguments[1]就是第二个参数,以此类推
这个对象只有在函数体内部,才可以使用
1 | |
正常模式下,arguments对象可以在运行时修改
1 | |
上面代码中,函数f()调用时传入的参数,在函数内部被修改成3和2
严格模式下,arguments对象与函数参数不具有联动关系
也就是说,修改arguments对象不会影响到实际的函数参数
1 | |
上面代码中,函数体内是严格模式,这时修改arguments对象,不会影响到真实参数a和b
通过arguments对象的length属性,可以判断函数调用时到底带几个参数
1 | |
(2)与数组的关系
需要注意的是,虽然arguments很像数组,但它是一个对象。数组专有的方法(比如slice和forEach),不能在arguments对象上直接使用
如果要让arguments对象使用数组方法,真正的解决方法是将arguments转为真正的数组。下面是两种常用的转换方法:slice方法和逐一填入新数组
1 | |
(3)callee 属性
arguments对象带有一个callee属性,返回它所对应的原函数
1 | |
可以通过arguments.callee,达到调用函数自身的目的
这个属性在严格模式里面是禁用的,因此不建议使用
函数的其他知识点
闭包
闭包(closure)是 JavaScript 语言的一个难点,也是它的特色,很多高级应用都要依靠闭包实现
理解闭包,首先必须理解变量作用域
前面提到,JavaScript 有两种作用域:全局作用域和函数作用域
函数内部可以直接读取全局变量
1 | |
上面代码中,函数f1可以读取全局变量n
但是,正常情况下,函数外部无法读取函数内部声明的变量
1 | |
上面代码中,函数f1内部声明的变量n,函数外是无法读取的
如果出于种种原因,需要得到函数内的局部变量
正常情况下,这是办不到的,只有通过变通方法才能实现。那就是在函数的内部,再定义一个函数
1 | |
上面代码中,函数f2就在函数f1内部,这时f1内部的所有局部变量,对f2都是可见的。但是反过来就不行,f2内部的局部变量,对f1就是不可见的
这就是 JavaScript 语言特有的”链式作用域”结构(chain scope),子对象会一级一级地向上寻找所有父对象的变量
所以,父对象的所有变量,对子对象都是可见的,反之则不成立
既然f2可以读取f1的局部变量,那么只要把f2作为返回值,我们不就可以在f1外部读取它的内部变量了吗!
1 | |
上面代码中,函数f1的返回值就是函数f2,由于f2可以读取f1的内部变量,所以就可以在外部获得f1的内部变量了
闭包就是函数f2,即能够读取其他函数内部变量的函数
由于在 JavaScript 语言中,只有函数内部的子函数才能读取内部变量,因此可以把闭包简单理解成“定义在一个函数内部的函数”
闭包最大的特点,就是它可以“记住”诞生的环境,比如f2记住了它诞生的环境f1,所以从f2可以得到f1的内部变量
在本质上,闭包就是将函数内部和函数外部连接起来的一座桥梁
闭包的最大用处有两个,一个是可以读取外层函数内部的变量,另一个就是让这些变量始终保持在内存中,即闭包可以使得它诞生环境一直存在
请看下面的例子,闭包使得内部变量记住上一次调用时的运算结果
1 | |
上面代码中,start是函数createIncrementor的内部变量
通过闭包,start的状态被保留了,每一次调用都是在上一次调用的基础上进行计算
从中可以看到,闭包inc使得函数createIncrementor的内部环境,一直存在
所以,闭包可以看作是函数内部作用域的一个接口
为什么闭包能够返回外层函数的内部变量?
原因是闭包(上例的inc)用到了外层变量(start),导致外层函数(createIncrementor)不能从内存释放
只要闭包没有被垃圾回收机制清除,外层函数提供的运行环境也不会被清除,它的内部变量就始终保存着当前值,供闭包读取
闭包的另一个用处,是封装对象的私有属性和私有方法
1 | |
上面代码中,函数Person的内部变量_age,通过闭包getAge和setAge,变成了返回对象p1的私有变量。
注意,外层函数每次运行,都会生成一个新的闭包,而这个闭包又会保留外层函数的内部变量,所以内存消耗很大
因此不能滥用闭包,否则会造成网页的性能问题
立即调用的函数表达式 IIFE
根据 JavaScript 的语法,圆括号()跟在函数名之后,表示调用该函数
比如,print()就表示调用print函数
有时,我们需要在定义函数之后,立即调用该函数
这时,你不能在函数的定义之后加上圆括号,这会产生语法错误
1 | |
产生这个错误的原因是,function这个关键字即可以当作语句,也可以当作表达式
1 | |
当作表达式时,函数可以定义后直接加圆括号调用
1 | |
上面的代码中,函数定义后直接加圆括号调用,没有报错
原因就是function作为表达式,引擎就把函数定义当作一个值。这种情况下,就不会报错
为了避免解析的歧义,JavaScript 规定,如果function关键字出现在行首,一律解释成语句
因此,引擎看到行首是function关键字之后,认为这一段都是函数的定义,不应该以圆括号结尾,所以就报错了
函数定义后立即调用的解决方法,就是不要让function出现在行首,让引擎将其理解成一个表达式
最简单的处理,就是将其放在一个圆括号里面
1 | |
上面两种写法都是以圆括号开头,引擎就会认为后面跟的是一个表达式,而不是函数定义语句,所以就避免了错误。这就叫做“立即调用的函数表达式”(Immediately-Invoked Function Expression),简称 IIFE
注意,上面两种写法最后的分号都是必须的。如果省略分号,遇到连着两个 IIFE,可能就会报错
1 | |
上面代码的两行之间没有分号,JavaScript 会将它们连在一起解释,将第二行解释为第一行的参数
推而广之,任何让解释器以表达式来处理函数定义的方法,都能产生同样的效果,比如下面三种写法。
1 | |
甚至像下面这样写,也是可以的
1 | |
通常情况下,只对匿名函数使用这种“立即执行的函数表达式”
它的目的有两个:
一是不必为函数命名,避免了污染全局变量
二是 IIFE 内部形成了一个单独的作用域,可以封装一些外部无法读取的私有变量
1 | |
上面代码中,写法二比写法一更好,因为完全避免了污染全局变量
eval 命令
基本用法
eval命令接受一个字符串作为参数,并将这个字符串当作语句执行
1 | |
上面代码将字符串当作语句运行,生成了变量a
如果参数字符串无法当作语句运行,那么就会报错
1 | |
放在eval中的字符串,应该有独自存在的意义,不能用来与eval以外的命令配合使用
举例来说,下面的代码将会报错
1 | |
上面代码会报错,因为return不能单独使用,必须在函数中使用
如果eval的参数不是字符串,那么会原样返回
1 | |
eval没有自己的作用域,都在当前作用域内执行,因此可能会修改当前作用域的变量的值,造成安全问题
1 | |
上面代码中,eval命令修改了外部变量a的值
由于这个原因,eval有安全风险
为了防止这种风险,JavaScript 规定,如果使用严格模式,eval内部声明的变量,不会影响到外部作用域
1 | |
上面代码中,函数f内部是严格模式,这时eval内部声明的foo变量,就不会影响到外部
不过,即使在严格模式下,eval依然可以读写当前作用域的变量
1 | |
上面代码中,严格模式下,eval内部还是改写了外部变量,可见安全风险依然存在
总之,eval的本质是在当前作用域之中,注入代码
由于安全风险和不利于 JavaScript 引擎优化执行速度,所以一般不推荐使用
通常情况下,eval最常见的场合是解析 JSON 数据的字符串,不过正确的做法应该是使用原生的JSON.parse方法
eval 的别名调用
前面说过eval不利于引擎优化执行速度。更麻烦的是,还有下面这种情况,引擎在静态代码分析的阶段,根本无法分辨执行的是eval
1 | |
上面代码中,变量m是eval的别名
静态代码分析阶段,引擎分辨不出m('var x = 1')执行的是eval命令
为了保证eval的别名不影响代码优化,JavaScript 的标准规定,凡是使用别名执行eval,eval内部一律是全局作用域
1 | |
上面代码中,eval是别名调用,所以即使它是在函数中,它的作用域还是全局作用域,因此输出的a为全局变量
这样的话,引擎就能确认e()不会对当前的函数作用域产生影响,优化的时候就可以把这一行排除掉
eval的别名调用的形式五花八门,只要不是直接调用,都属于别名调用,因为引擎只能分辨eval()这一种形式是直接调用
1 | |
上面这些形式都是eval的别名调用,作用域都是全局作用域
Array 数组
定义
数组(array)是按次序排列的一组值
每个值的位置都有编号(从0开始),整个数组用方括号表示
1 | |
上面代码中的a、b、c就构成一个数组,两端的方括号是数组的标志。a是0号位置,b是1号位置,c是2号位置
除了在定义时赋值,数组也可以先定义后赋值
1 | |
任何类型的数据,都可以放入数组
1 | |
上面数组arr的3个成员依次是对象、数组、函数
如果数组的元素还是数组,就形成了多维数组
1 | |
数组的本质
本质上,数组属于一种特殊的对象。typeof运算符会返回数组的类型是object
1 | |
上面代码表明,typeof运算符认为数组的类型就是对象
数组的特殊性体现在,它的键名是按次序排列的一组整数(0,1,2…)
1 | |
上面代码中,Object.keys方法返回数组的所有键名
可以看到数组的键名就是整数0、1、2
由于数组成员的键名是固定的(默认总是0、1、2…),因此数组不用为每个元素指定键名,而对象的每个成员都必须指定键名JavaScript 语言规定,对象的键名一律为字符串,所以,数组的键名其实也是字符串
之所以可以用数值读取,是因为非字符串的键名会被转为字符串
1 | |
上面代码分别用数值和字符串作为键名,结果都能读取数组。原因是数值键名被自动转为了字符串
注意,这点在赋值时也成立。一个值总是先转成字符串,再作为键名进行赋值
1 | |
上面代码中,由于1.00转成字符串是1,所以通过数字键1可以读取值
上一章说过,对象有两种读取成员的方法:点结构(object.key)和方括号结构(object[key])。但是,对于数值的键名,不能使用点结构
1 | |
上面代码中,arr.0的写法不合法,因为单独的数值不能作为标识符(identifier)。所以,数组成员只能用方括号arr[0]表示(方括号是运算符,可以接受数值)
length 属性
数组的length属性,返回数组的成员数量
1 | |
JavaScript 使用一个32位整数,保存数组的元素个数
这意味着,数组成员最多只有 4294967295 个(232 - 1)个,也就是说length属性的最大值就是 4294967295
只要是数组,就一定有length属性
该属性是一个动态的值,等于键名中的最大整数加上1
1 | |
上面代码表示,数组的数字键不需要连续,length属性的值总是比最大的那个整数键大1
另外,这也表明数组是一种动态的数据结构,可以随时增减数组的成员
length属性是可写的。如果人为设置一个小于当前成员个数的值,该数组的成员数量会自动减少到length设置的值
1 | |
上面代码表示,当数组的length属性设为2(即最大的整数键只能是1)那么整数键2(值为c)就已经不在数组中了,被自动删除了
清空数组的一个有效方法,就是将length属性设为0
1 | |
如果人为设置length大于当前元素个数,则数组的成员数量会增加到这个值,新增的位置都是空位
1 | |
上面代码表示,当length属性设为大于数组个数时,读取新增的位置都会返回undefined
如果人为设置length为不合法的值,JavaScript 会报错
1 | |
值得注意的是,由于数组本质上是一种对象,所以可以为数组添加属性,但是这不影响length属性的值
1 | |
上面代码将数组的键分别设为字符串和小数,结果都不影响length属性
因为,length属性的值就是等于最大的数字键加1,而这个数组没有整数键,所以length属性保持为0
如果数组的键名是添加超出范围的数值,该键名会自动转为字符串
1 | |
上面代码中,我们为数组arr添加了两个不合法的数字键,结果length属性没有发生变化
这些数字键都变成了字符串键名。最后两行之所以会取到值,是因为取键值时,数字键名会默认转为字符串
in 运算符
检查某个键名是否存在的运算符in,适用于对象,也适用于数组
1 | |
上面代码表明,数组存在键名为2的键。由于键名都是字符串,所以数值2会自动转成字符串
注意,如果数组的某个位置是空位,in运算符返回false
1 | |
上面代码中,数组arr只有一个成员arr[100],其他位置的键名都会返回false
for…in 循环和数组的遍历
for...in循环不仅可以遍历对象,也可以遍历数组,毕竟数组只是一种特殊对象
1 | |
但是,for...in不仅会遍历数组所有的数字键,还会遍历非数字键
1 | |
上面代码在遍历数组时,也遍历到了非整数键foo。所以,不推荐使用for...in遍历数组
数组的遍历可以考虑使用for循环或while循环
1 | |
上面代码是三种遍历数组的写法。最后一种写法是逆向遍历,即从最后一个元素向第一个元素遍历
1 | |
数组的空位
当数组的某个位置是空元素,即两个逗号之间没有任何值,我们称该数组存在空位(hole)
1 | |
上面代码表明,数组的空位不影响length属性
需要注意的是,如果最后一个元素后面有逗号,并不会产生空位。也就是说,有没有这个逗号,结果都是一样的
1 | |
上面代码中,数组最后一个成员后面有一个逗号,这不影响length属性的值,与没有这个逗号时效果一样
数组的空位是可以读取的,返回undefined
1 | |
使用delete命令删除一个数组成员,会形成空位,并且不会影响length属性。
1 | |
上面代码用delete命令删除了数组的第二个元素,这个位置就形成了空位,但是对length属性没有影响
也就是说,length属性不过滤空位
所以,使用length属性进行数组遍历,一定要非常小心
数组的某个位置是空位,与某个位置是undefined,是不一样的
如果是空位,使用数组的forEach方法、for...in结构、以及Object.keys方法进行遍历,空位都会被跳过
1 | |
如果某个位置是undefined,遍历的时候就不会被跳过
1 | |
这就是说,空位就是数组没有这个元素,所以不会被遍历到,而undefined则表示数组有这个元素,值是undefined,所以遍历不会跳过
类似数组的对象
如果一个对象的所有键名都是正整数或零,并且有length属性,那么这个对象就很像数组,语法上称为“类似数组的对象”(array-like object)
1 | |
上面代码中,对象obj就是一个类似数组的对象。但是,“类似数组的对象”并不是数组,因为它们不具备数组特有的方法
对象obj没有数组的push方法,使用该方法就会报错
“类似数组的对象”的根本特征,就是具有length属性
只要有length属性,就可以认为这个对象类似于数组
但是有一个问题,这种length属性不是动态值,不会随着成员的变化而变化
1 | |
上面代码为对象obj添加了一个数字键,但是length属性没变。这就说明了obj不是数组
典型的“类似数组的对象”是函数的arguments对象,以及大多数 DOM 元素集,还有字符串
1 | |
上面代码包含三个例子,它们都不是数组(instanceof运算符返回false),但是看上去都非常像数组
数组的slice方法可以将“类似数组的对象”变成真正的数组
1 | |
除了转为真正的数组,“类似数组的对象”还有一个办法可以使用数组的方法,就是通过call()把数组的方法放到对象上面
1 | |
上面代码中,arrayLike代表一个类似数组的对象,本来是不可以使用数组的forEach()方法的,但是通过call(),可以把forEach()嫁接到arrayLike上面调用
下面的例子就是通过这种方法,在arguments对象上面调用forEach方法
1 | |
字符串也是类似数组的对象,所以也可以用Array.prototype.forEach.call遍历
1 | |
注意,这种方法比直接使用数组原生的forEach要慢,所以最好还是先将“类似数组的对象”转为真正的数组,然后再直接调用数组的forEach方法
1 | |
运算符
算术运算符
JavaScript 共提供10个算术运算符,用来完成基本的算术运算
加法运算符:x + y
减法运算符: x - y
乘法运算符: x * y
除法运算符:x / y
指数运算符:x ** y
余数运算符:x % y
自增运算符:++x 或者 x++
自减运算符:--x 或者 x--
数值运算符: +x
负数值运算符:-x
减法、乘法、除法运算法比较单纯,就是执行相应的数学运算,重点是加法运算符
加法运算符
基本规则
加法运算符(+)是最常见的运算符,用来求两个数值的和
1 | |
JavaScript 允许非数值的相加
1 | |
上面代码中,第一行是两个布尔值相加,第二行是数值与布尔值相加
这两种情况,布尔值都会自动转成数值,然后再相加
比较特殊的是,如果是两个字符串相加,这时加法运算符会变成连接运算符,返回一个新的字符串,将两个原字符串连接在一起
1 | |
如果一个运算子是字符串,另一个运算子是非字符串,这时非字符串会转成字符串,再连接在一起
1 | |
加法运算符是在运行时决定,到底是执行相加,还是执行连接
也就是说,运算子的不同,导致了不同的语法行为,这种现象称为“重载”(overload)
由于加法运算符存在重载,可能执行两种运算,使用的时候必须很小心
1 | |
上面代码中,由于从左到右的运算次序,字符串的位置不同会导致不同的结果
除了加法运算符,其他算术运算符(比如减法、除法和乘法)都不会发生重载
它们的规则是:所有运算子一律转为数值,再进行相应的数学运算
1 | |
上面代码中,减法、除法和乘法运算符,都是将字符串自动转为数值,然后再运算
对象的相加
如果运算子是对象,必须先转成原始类型的值,然后再相加
1 | |
上面代码中,对象obj转成原始类型的值是[object Object],再加2就得到了上面的结果
对象转成原始类型的值,规则如下。
首先,自动调用对象的valueOf方法
1 | |
一般来说,对象的valueOf方法总是返回对象自身,这时再自动调用对象的toString方法,将其转为字符串
1 | |
对象的toString方法默认返回[object Object],所以就得到了最前面那个例子的结果
知道了这个规则以后,就可以自己定义valueOf方法或toString方法,得到想要的结果
1 | |
上面代码中,我们定义 obj对象的valueOf方法返回1,于是 obj + 2 就得到了3
这个例子中,由于valueOf方法直接返回一个原始类型的值,所以不再调用toString方法
下面是自定义toString方法的例子
1 | |
上面代码中,对象obj的toString方法返回字符串hello
前面说过,只要有一个运算子是字符串,加法运算符就变成连接运算符,返回连接后的字符串
这里有一个特例,如果运算子是一个 Date对象的实例,那么会优先执行toString方法
1 | |
上面代码中,对象obj是一个Date对象的实例,并且自定义了valueOf方法和toString方法,结果toString方法优先执行
余数运算符
余数运算符(%)返回前一个运算子被后一个运算子除,所得的余数
1 | |
需要注意的是,运算结果的正负号由第一个运算子的正负号决定
1 | |
所以,为了得到负数的正确余数值,可以先使用绝对值函数
1 | |
余数运算符还可以用于浮点数的运算。但是,由于浮点数不是精确的值,无法得到完全准确的结果
1 | |
自增和自减运算符
自增和自减运算符,是一元运算符,只需要一个运算子
它们的作用是将运算子首先转为数值,然后加上1或者减去1
它们会修改原始变量
1 | |
上面代码的变量x自增后,返回2,再进行自减,返回1
这两种情况都会使得,原始变量x的值发生改变
运算之后,变量的值发生变化,这种效应叫做运算的副作用(side effect)
自增和自减运算符是仅有的两个具有副作用的运算符,其他运算符都不会改变变量的值
自增和自减运算符有一个需要注意的地方,就是放在变量之后,会先返回变量操作前的值,再进行自增/自减操作;放在变量之前,会先进行自增/自减操作,再返回变量操作后的值
1 | |
上面代码中,x是先返回当前值,然后自增,所以得到1;y是先自增,然后返回新的值,所以得到2
数值运算符,负数值运算符
数值运算符(+)同样使用加号,但它是一元运算符(只需要一个操作数),而加法运算符是二元运算符(需要两个操作数)
数值运算符的作用在于可以将任何值转为数值(与Number函数的作用相同)
1 | |
上面代码表示,非数值经过数值运算符以后,都变成了数值(最后一行NaN也是数值)
负数值运算符(-),也同样具有将一个值转为数值的功能,只不过得到的值正负相反
连用两个负数值运算符,等同于数值运算符
1 | |
上面代码最后一行的圆括号不可少,否则会变成自减运算符
数值运算符号和负数值运算符,都会返回一个新的值,而不会改变原始变量的值
指数运算符
指数运算符(**)完成指数运算,前一个运算子是底数,后一个运算子是指数
1 | |
注意,指数运算符是右结合,而不是左结合。即多个指数运算符连用时,先进行最右边的计算
1 | |
上面代码中,由于指数运算符是右结合,所以先计算第二个指数运算符,而不是第一个
赋值运算符
赋值运算符(Assignment Operators)用于给变量赋值
最常见的赋值运算符,当然就是等号(=)
1 | |
赋值运算符还可以与其他运算符结合,形成变体
下面是与算术运算符的结合
1 | |
下面是与位运算符的结合(关于位运算符,请见后文的介绍)
1 | |
这些复合的赋值运算符,都是先进行指定运算,然后将得到值返回给左边的变量
比较运算符
比较运算符用于比较两个值的大小,然后返回一个布尔值,表示是否满足指定的条件
1 | |
上面代码比较2是否大于1,返回true
注意,比较运算符可以比较各种类型的值,不仅仅是数值
JavaScript 一共提供了8个比较运算符
>大于运算符<小于运算符<=小于或等于运算符>=大于或等于运算符==相等运算符===严格相等运算符!=不相等运算符!==严格不相等运算符
这八个比较运算符分成两类:相等比较和非相等比较
两者的规则是不一样的,对于非相等的比较,算法是先看两个运算子是否都是字符串,如果是的,就按照字典顺序比较(实际上是比较 Unicode 码点);否则,将两个运算子都转成数值,再比较数值的大小。
非相等运算符:字符串的比较
字符串按照字典顺序进行比较
1 | |
JavaScript 引擎内部首先比较首字符的 Unicode 码点
如果相等,再比较第二个字符的 Unicode 码点,以此类推
1 | |
上面代码中,小写的c的Unicode 码点(99)大于大写的C的 Unicode 码点(67),所以返回true。
由于所有字符都有 Unicode 码点,因此汉字也可以比较
1 | |
上面代码中,“大”的 Unicode 码点是22823,“小”是23567,因此返回false
非相等运算符:非字符串的比较
如果两个运算子之中,至少有一个不是字符串,需要分成以下两种情况
(1)原始类型值
如果两个运算子都是原始类型的值,则是先转成数值再比较
1 | |
上面代码中,字符串和布尔值都会先转成数值,再进行比较
这里需要注意与NaN的比较。任何值(包括NaN本身)与NaN使用非相等运算符进行比较,返回的都是false
1 | |
(2)对象
如果运算子是对象,会转为原始类型的值,再进行比较
对象转换成原始类型的值,算法是先调用valueOf方法
如果返回的还是对象,再接着调用toString方法
1 | |
两个对象之间的比较也是如此
1 | |
严格相等运算符
JavaScript 提供两种相等运算符:==和===。
简单说,它们的区别是相等运算符(==)比较两个值是否相等,严格相等运算符(===)比较它们是否为“同一个值”
如果两个值不是同一类型,严格相等运算符(===)直接返回false,而相等运算符(==)会将它们转换成同一个类型,再用严格相等运算符进行比较
(1)不同类型的值
如果两个值的类型不同,直接返回false
1 | |
上面代码比较数值的1与字符串的“1”、布尔值的true与字符串"true",因为类型不同,结果都是false
(2)同一类的原始类型值
同一类型的原始类型的值(数值、字符串、布尔值)比较时,值相同就返回true,值不同就返回false
1 | |
上面代码比较十进制的1与十六进制的1,因为类型和值都相同,返回true
需要注意的是,NaN与任何值都不相等(包括自身)
另外,正0等于负0
1 | |
(3)复合类型值
两个复合类型(对象、数组、函数)的数据比较时,不是比较它们的值是否相等,而是比较它们是否指向同一个地址
1 | |
上面代码分别比较两个空对象、两个空数组、两个空函数,结果都是不相等
原因是对于复合类型的值,严格相等运算比较的是,它们是否引用同一个内存地址,而运算符两边的空对象、空数组、空函数的值,都存放在不同的内存地址,结果当然是false
如果两个变量引用同一个对象,则它们相等
1 | |
注意,对于两个对象的比较,严格相等运算符比较的是地址,而大于或小于运算符比较的是值
1 | |
上面的三个比较,前两个比较的是值,最后一个比较的是地址,所以都返回false
(4)undefined 和 null
undefined和null与自身严格相等
1 | |
由于变量声明后默认值是undefined,因此两个只声明未赋值的变量是相等的
1 | |
严格不相等运算符
严格相等运算符有一个对应的“严格不相等运算符”(!==),它的算法就是先求严格相等运算符的结果,然后返回相反值
1 | |
上面代码中,感叹号!是求出后面表达式的相反值
相等运算符
相等运算符用来比较相同类型的数据时,与严格相等运算符完全一样
1 | |
比较不同类型的数据时,相等运算符会先将数据进行类型转换,然后再用严格相等运算符比较
下面分成几种情况,讨论不同类型的值互相比较的规则
(1)原始类型值
原始类型的值会转换成数值再进行比较
1 | |
上面代码将字符串和布尔值都转为数值,然后再进行比较
(2)对象与原始类型值比较
对象(这里指广义的对象,包括数组和函数)与原始类型的值比较时,对象转换成原始类型的值,再进行比较
具体来说,先调用对象的valueOf()方法,如果得到原始类型的值,就按照上一小节的规则,互相比较;如果得到的还是对象,则再调用toString()方法,得到字符串形式,再进行比较
下面是数组与原始类型值比较的例子
1 | |
上面例子中,Javascript 引擎会先对数组[1]调用数组的valueOf()方法,由于返回的还是一个数组,所以会接着调用数组的toString()方法,得到字符串形式,再按照上一小节的规则进行比较
下面是一个更直接的例子
1 | |
上面例子中,obj是一个自定义了valueOf()和toString()方法的对象。这个对象与字符串'foo'进行比较时,会依次调用valueOf()和toString()方法,最后返回'foo',所以比较结果是true。
(3)undefined 和 null
undefined和null只有与自身比较,或者互相比较时,才会返回true;与其他类型的值比较时,结果都为false
1 | |
(4)相等运算符的缺点
相等运算符隐藏的类型转换,会带来一些违反直觉的结果
1 | |
上面这些表达式都不同于直觉,很容易出错
因此建议不要使用相等运算符(==),最好只使用严格相等运算符(===)。
不相等运算符
相等运算符有一个对应的“不相等运算符”(!=),它的算法就是先求相等运算符的结果,然后返回相反值
1 | |
布尔运算符
概述
布尔运算符用于将表达式转为布尔值,一共包含四个运算符
- 取反运算符:
! - 且运算符:
&& - 或运算符:
|| - 三元运算符:
?:
取反运算符 !
取反运算符是一个感叹号,用于将布尔值变为相反值,即true变成false,false变成true
1 | |
对于非布尔值,取反运算符会将其转为布尔值。可以这样记忆,以下六个值取反后为true,其他值都为false
undefinednullfalse0NaN- 空字符串(
'')
1 | |
上面代码中,不管什么类型的值,经过取反运算后,都变成了布尔值
如果对一个值连续做两次取反运算,等于将其转为对应的布尔值,与Boolean函数的作用相同
这是一种常用的类型转换的写法
1 | |
上面代码中,不管x是什么类型的值,经过两次取反运算后,变成了与Boolean函数结果相同的布尔值
所以,两次取反就是将一个值转为布尔值的简便写法
且运算符 &&
且运算符(&&)往往用于多个表达式的求值
运算规则:
如果第一个运算子的布尔值为true,则返回第二个运算子的值(注意是值,不是布尔值)
如果第一个运算子的布尔值为false,则直接返回第一个运算子的值,且不再对第二个运算子求值
1 | |
上面代码的最后一个例子,由于且运算符的第一个运算子的布尔值为false,则直接返回它的值0,而不再对第二个运算子求值,所以变量x的值没变
这种跳过第二个运算子的机制,被称为“短路”
有些程序员喜欢用它取代if结构,比如下面是一段if结构的代码,就可以用且运算符改写
1 | |
上面代码的两种写法是等价的,但是后一种不容易看出目的,也不容易除错,建议谨慎使用
且运算符可以多个连用,这时返回第一个布尔值为false的表达式的值。如果所有表达式的布尔值都为true,则返回最后一个表达式的值
1 | |
上面代码中,例一里面,第一个布尔值为false的表达式为第三个表达式,所以得到一个空字符串
例二里面,所有表达式的布尔值都是true,所以返回最后一个表达式的值3
或运算符 ||
或运算符(||)也用于多个表达式的求值
它的运算规则是:如果第一个运算子的布尔值为true,则返回第一个运算子的值,且不再对第二个运算子求值;如果第一个运算子的布尔值为false,则返回第二个运算子的值
1 | |
短路规则对这个运算符也适用
1 | |
上面代码中,或运算符的第一个运算子为true,所以直接返回true,不再运行第二个运算子
所以,x的值没有改变。这种只通过第一个表达式的值,控制是否运行第二个表达式的机制,就称为“短路”(short-cut)
或运算符可以多个连用,这时返回第一个布尔值为true的表达式的值
如果所有表达式都为false,则返回最后一个表达式的值
1 | |
上面代码中,例一里面,第一个布尔值为true的表达式是第四个表达式,所以得到数值4
例二里面,所有表达式的布尔值都为false,所以返回最后一个表达式的值
或运算符常用于为一个变量设置默认值
1 | |
上面代码表示,如果函数调用时,没有提供参数,则该参数默认设置为空字符串
三元条件运算符 ?:
三元条件运算符由问号?和冒号:组成,分隔三个表达式
它是 JavaScript 语言唯一一个需要三个运算子的运算符
如果第一个表达式的布尔值为true,则返回第二个表达式的值,否则返回第三个表达式的值
1 | |
上面代码的t和0的布尔值分别为true和false,所以分别返回第二个和第三个表达式的值
通常来说,三元条件表达式与if...else语句具有同样表达效果,前者可以表达的,后者也能表达
但是两者具有一个重大差别,if...else是语句,没有返回值;三元条件表达式是表达式,具有返回值
所以,在需要返回值的场合,只能使用三元条件表达式,而不能使用if..else
1 | |
上面代码中,console.log方法的参数必须是一个表达式,这时就只能使用三元条件表达式
如果要用if...else语句,就必须改变整个代码写法了
二进制位运算符
概述
二进制位运算符用于直接对二进制位进行计算,一共有7个。
- 二进制或运算符(or):符号为
|,表示若两个二进制位都为0,则结果为0,否则为1。 - 二进制与运算符(and):符号为
&,表示若两个二进制位都为1,则结果为1,否则为0。 - 二进制否运算符(not):符号为
~,表示对一个二进制位取反。 - 异或运算符(xor):符号为
^,表示若两个二进制位不相同,则结果为1,否则为0。 - 左移运算符(left shift):符号为
<<,详见下文解释。 - 右移运算符(right shift):符号为
>>,详见下文解释。 - 头部补零的右移运算符(zero filled right shift):符号为
>>>,详见下文解释。
这些位运算符直接处理每一个比特位(bit),所以是非常底层的运算,好处是速度极快,缺点是很不直观,许多场合不能使用它们,否则会使代码难以理解和查错。
有一点需要特别注意,位运算符只对整数起作用,如果一个运算子不是整数,会自动转为整数后再执行。另外,虽然在 JavaScript 内部,数值都是以64位浮点数的形式储存,但是做位运算的时候,是以32位带符号的整数进行运算的,并且返回值也是一个32位带符号的整数。
1 | |
上面这行代码的意思,就是将i(不管是整数或小数)转为32位整数。
利用这个特性,可以写出一个函数,将任意数值转为32位整数。
1 | |
上面这个函数将任意值与0进行一次或运算,这个位运算会自动将一个值转为32位整数。下面是这个函数的用法。
1 | |
上面代码中,toInt32可以将小数转为整数。对于一般的整数,返回值不会有任何变化。对于大于或等于2的32次方的整数,大于32位的数位都会被舍去。
二进制或运算符
二进制或运算符(|)逐位比较两个运算子,两个二进制位之中只要有一个为1,就返回1,否则返回0
1 | |
上面代码中,0和3的二进制形式分别是00和11,所以进行二进制或运算会得到11(即3)
位运算只对整数有效,遇到小数时,会将小数部分舍去,只保留整数部分
所以,将一个小数与0进行二进制或运算,等同于对该数去除小数部分,即取整数位
1 | |
需要注意的是,这种取整方法不适用超过32位整数最大值2147483647的数
1 | |
二进制与运算符
二进制与运算符(&)的规则是逐位比较两个运算子,两个二进制位之中只要有一个位为0,就返回0,否则返回1
1 | |
上面代码中,0(二进制00)和3(二进制11)进行二进制与运算会得到00(即0)。
二进制否运算符
二进制否运算符(~)将每个二进制位都变为相反值(0变为1,1变为0)
它的返回结果有时比较难理解,因为涉及到计算机内部的数值表示机制
1 | |
上面表达式对3进行二进制否运算,得到-4。之所以会有这样的结果,是因为位运算时,JavaScript 内部将所有的运算子都转为32位的二进制整数再进行运算。
3的32位整数形式是00000000000000000000000000000011,二进制否运算以后得到11111111111111111111111111111100
由于第一位(符号位)是1,所以这个数是一个负数
JavaScript 内部采用补码形式表示负数,即需要将这个数减去1,再取一次反,然后加上负号,才能得到这个负数对应的10进制值
这个数减去1等于11111111111111111111111111111011,再取一次反得到00000000000000000000000000000100,再加上负号就是-4
考虑到这样的过程比较麻烦,可以简单记忆成,一个数与自身的取反值相加,等于-1。
1 | |
上面表达式可以这样算,-3的取反值等于-1减去-3,结果为2
对一个整数连续两次二进制否运算,得到它自身
1 | |
所有的位运算都只对整数有效
二进制否运算遇到小数时,也会将小数部分舍去,只保留整数部分
所以,对一个小数连续进行两次二进制否运算,能达到取整效果
1 | |
使用二进制否运算取整,是所有取整方法中最快的一种
对字符串进行二进制否运算,Javascript 引擎会先调用Number函数,将字符串转为数值
1 | |
对于其他类型的值,二进制否运算也是先用Number转为数值,然后再进行处理
1 | |
异或运算符
异或运算(^)在两个二进制位不同时返回1,相同时返回0
1 | |
上面表达式中,0(二进制00)与3(二进制11)进行异或运算,它们每一个二进制位都不同,所以得到11(即3)
“异或运算”有一个特殊运用,连续对两个数a和b进行三次异或运算,a^=b; b^=a; a^=b;,可以互换它们的值
这意味着,使用“异或运算”可以在不引入临时变量的前提下,互换两个变量的值
1 | |
这是互换两个变量的值的最快方法
异或运算也可以用来取整
1 | |
左移运算符
左移运算符(<<)表示将一个数的二进制值向左移动指定的位数,尾部补0,即乘以2的指定次方
向左移动的时候,最高位的符号位是一起移动的
1 | |
上面代码中,-4左移一位得到-8,是因为-4的二进制形式是11111111111111111111111111111100,左移一位后得到11111111111111111111111111111000,该数转为十进制(减去1后取反,再加上负号)即为-8
如果左移0位,就相当于将该数值转为32位整数,等同于取整,对于正数和负数都有效
1 | |
左移运算符用于二进制数值非常方便
1 | |
上面代码使用左移运算符,将颜色的 RGB 值转为 HEX 值
右移运算符
右移运算符(>>)表示将一个数的二进制值向右移动指定的位数
如果是正数,头部全部补0;如果是负数,头部全部补1
右移运算符基本上相当于除以2的指定次方(最高位即符号位参与移动)
1 | |
右移运算可以模拟 2 的整除运算
1 | |
头部补零的右移运算符
头部补零的右移运算符(>>>)与右移运算符(>>)只有一个差别,就是一个数的二进制形式向右移动时,头部一律补零,而不考虑符号位
所以,该运算总是得到正值
对于正数,该运算的结果与右移运算符(>>)完全一致,区别主要在于负数
1 | |
这个运算实际上将一个值转为32位无符号整数
查看一个负整数在计算机内部的储存形式,最快的方法就是使用这个运算符
1 | |
上面代码表示,-1作为32位整数时,内部的储存形式使用无符号整数格式解读,值为 4294967295(即(2^32)-1,等于11111111111111111111111111111111)。
开关作用
位运算符可以用作设置对象属性的开关。
假定某个对象有四个开关,每个开关都是一个变量。那么,可以设置一个四位的二进制数,它的每个位对应一个开关
1 | |
上面代码设置 A、B、C、D 四个开关,每个开关分别占有一个二进制位
然后,就可以用二进制与运算,检查当前设置是否打开了指定开关
1 | |
上面代码检验是否打开了开关C。如果打开,会返回true,否则返回false
现在假设需要打开A、B、D三个开关,我们可以构造一个掩码变量。
1 | |
上面代码对A、B、D三个变量进行二进制或运算,得到掩码值为二进制的1011
有了掩码,二进制或运算可以确保打开指定的开关
1 | |
上面代码中,计算后得到的flags变量,代表三个开关的二进制位都打开了
二进制与运算可以将当前设置中凡是与开关设置不一样的项,全部关闭
1 | |
异或运算可以切换(toggle)当前设置,即第一次执行可以得到当前设置的相反值,再执行一次又得到原来的值
1 | |
二进制否运算可以翻转当前设置,即原设置为0,运算后变为1;原设置为1,运算后变为0
1 | |
void 运算符
void运算符的作用是执行一个表达式,然后不返回任何值,或者说返回undefined
1 | |
上面是void运算符的两种写法,都正确。建议采用后一种形式,即总是使用圆括号
因为void运算符的优先性很高,如果不使用括号,容易造成错误的结果
比如,void 4 + 7实际上等同于(void 4) + 7。
下面是void运算符的一个例子。
1 | |
这个运算符的主要用途是浏览器的书签工具(Bookmarklet),以及在超级链接中插入代码防止网页跳转
1 | |
上面代码中,点击链接后,会先执行onclick的代码,由于onclick返回false,所以浏览器不会跳转到 example.com
void运算符可以取代上面的写法
1 | |
下面是一个更实际的例子,用户点击链接提交表单,但是不产生页面跳转
1 | |
逗号运算符
逗号运算符用于对两个表达式求值,并返回后一个表达式的值
1 | |
上面代码中,逗号运算符返回后一个表达式的值。
逗号运算符的一个用途是,在返回一个值之前,进行一些辅助操作
1 | |
上面代码中,先执行逗号之前的操作,然后返回逗号后面的值
运算顺序
优先级
Javascript 各种运算符的优先级别(Operator Precedence)是不一样的。优先级高的运算符先执行,优先级低的运算符后执行
1 | |
上面的代码中,乘法运算符*的优先性高于加法运算符+,所以先执行乘法,再执行加法,相当于下面这样
1 | |
如果多个运算符混写在一起,常常会导致令人困惑的代码
1 | |
上面代码中,变量y的值就很难看出来,因为这个表达式涉及5个运算符,到底谁的优先级最高,实在不容易记住
根据语言规格,这五个运算符的优先级从高到低依次为:
小于等于(<=)、严格相等(===)、或(||)、三元(?:)、等号(=)
因此上面的表达式,实际的运算顺序如下
1 | |
记住所有运算符的优先级,是非常难的,也是没有必要的
圆括号的作用
圆括号(())可以用来提高运算的优先级,因为它的优先级是最高的,即圆括号中的表达式会第一个运算
1 | |
上面代码中,由于使用了圆括号,加法会先于乘法执行
运算符的优先级别十分繁杂,且都是硬性规定,因此建议总是使用圆括号,保证运算顺序清晰可读,这对代码的维护和除错至关重要
顺便说一下,圆括号不是运算符,而是一种语法结构。它一共有两种用法:
- 把表达式放在圆括号之中,提升运算的优先级
- 跟在函数的后面,作用是调用函数
注意,因为圆括号不是运算符,所以不具有求值作用,只改变运算的优先级
1 | |
上面代码的第二行,如果圆括号具有求值作用,那么就会变成1 = 2,这是会报错了
但是,上面的代码可以运行,这验证了圆括号只改变优先级,不会求值
这也意味着,如果整个表达式都放在圆括号之中,那么不会有任何效果
1 | |
函数放在圆括号中,会返回函数本身。如果圆括号紧跟在函数的后面,就表示调用函数
1 | |
上面代码中,函数放在圆括号之中会返回函数本身,圆括号跟在函数后面则是调用函数
圆括号之中,只能放置表达式,如果将语句放在圆括号之中,就会报错
1 | |
左结合与右结合
对于优先级别相同的运算符,同时出现的时候,就会有计算顺序的问题
1 | |
上面代码中,OP表示运算符。它可以有两种解释方式
1 | |
上面的两种方式,得到的计算结果往往是不一样的
方式一是将左侧两个运算数结合在一起,采用这种解释方式的运算符,称为“左结合”(left-to-right associativity)运算符
方式二是将右侧两个运算数结合在一起,这样的运算符称为“右结合”运算符(right-to-left associativity)
JavaScript 语言的大多数运算符是“左结合”,请看下面加法运算符的例子
1 | |
上面代码中,x与y结合在一起,它们的预算结果再与z进行运算
少数运算符是“右结合”,其中最主要的是赋值运算符(=)和三元条件运算符(?:)
1 | |
上面代码的解释方式如下。
1 | |
上面的两行代码,都是右侧的运算数结合在一起。
另外,指数运算符(**)也是右结合。
1 | |
数据类型的转换
Javascript 是一种动态类型语言,变量没有类型限制,可以随时赋予任意值
1 | |
上面代码中,变量x到底是数值还是字符串,取决于另一个变量y的值
y为true时,x是一个数值;y为false时,x是一个字符串
这意味着,x的类型没法在编译阶段就知道,必须等到运行时才能知道
虽然变量的数据类型是不确定的,但是各种运算符对数据类型是有要求的
如果运算符发现,运算子的类型与预期不符,就会自动转换类型
比如,减法运算符预期左右两侧的运算子应该是数值,如果不是,就会自动将它们转为数值
1 | |
上面代码中,虽然是两个字符串相减,但是依然会得到结果数值1,原因就在于 Javascript 将运算子自动转为了数值
本章讲解数据类型自动转换的规则。在此之前,先讲解如何手动强制转换数据类型
强制转换
强制转换主要指使用Number()、String()和Boolean()三个函数,手动将各种类型的值,分别转换成数字、字符串或者布尔值
Number()
使用Number函数,可以将任意类型的值转化成数值
下面分成两种情况讨论,一种是参数是原始类型的值,另一种是参数是对象
(1)原始类型值
原始类型值的转换规则如下
1 | |
Number函数将字符串转为数值,要比parseInt函数严格很多
基本上,只要有一个字符无法转成数值,整个字符串就会被转为NaN
1 | |
上面代码中,parseInt逐个解析字符,而Number函数整体转换字符串的类型
另外,parseInt和Number函数都会自动过滤一个字符串前导和后缀的空格
1 | |
(2)对象
简单的规则是,Number方法的参数是对象时,将返回NaN,除非是包含单个数值的数组
1 | |
之所以会这样,是因为Number背后的转换规则比较复杂
调用对象自身的
valueOf方法。如果返回原始类型的值,则直接对该值使用Number函数,不再进行后续步骤如果
valueOf方法返回的还是对象,则改为调用对象自身的toString方法。如果toString方法返回原始类型的值,则对该值使用Number函数,不再进行后续步骤如果
toString方法返回的是对象,就报错
1 | |
上面代码中,Number函数将obj对象转为数值。背后发生了一连串的操作,首先调用obj.valueOf方法, 结果返回对象本身;于是,继续调用obj.toString方法,这时返回字符串[object Object],对这个字符串使用Number函数,得到NaN
默认情况下,对象的valueOf方法返回对象本身,所以一般总是会调用toString方法,而toString方法返回对象的类型字符串(比如[object Object])。所以,会有下面的结果
1 | |
如果toString方法返回的不是原始类型的值,结果就会报错
1 | |
上面代码的valueOf和toString方法,返回的都是对象,所以转成数值时会报错
从上例还可以看到,valueOf和toString方法,都是可以自定义的
1 | |
上面代码对三个对象使用Number函数。第一个对象返回valueOf方法的值,第二个对象返回toString方法的值,第三个对象表示valueOf方法先于toString方法执行
String()
String函数可以将任意类型的值转化成字符串,转换规则如下
(1)原始类型值
- 数值:转为相应的字符串
- 字符串:转换后还是原来的值
- 布尔值:
true转为字符串"true",false转为字符串"false" - undefined:转为字符串
"undefined" - null:转为字符串
"null"
1 | |
(2)对象
String方法的参数如果是对象,返回一个类型字符串;如果是数组,返回该数组的字符串形式
1 | |
String方法背后的转换规则,与Number方法基本相同,只是互换了valueOf方法和toString方法的执行顺序
先调用对象自身的
toString方法。如果返回原始类型的值,则对该值使用String函数,不再进行以下步骤。如果
toString方法返回的是对象,再调用原对象的valueOf方法。如果valueOf方法返回原始类型的值,则对该值使用String函数,不再进行以下步骤如果
valueOf方法返回的是对象,就报错
下面是一个例子。
1 | |
上面代码先调用对象的toString方法,发现返回的是字符串[object Object],就不再调用valueOf方法了
如果toString法和valueOf方法,返回的都是对象,就会报错
1 | |
下面是通过自定义toString方法,改变返回值的例子
1 | |
上面代码对三个对象使用String函数。第一个对象返回toString方法的值(数值3),第二个对象返回的还是toString方法的值([object Object]),第三个对象表示toString方法先于valueOf方法执行
Boolean()
Boolean()函数可以将任意类型的值转为布尔值
它的转换规则相对简单:除了以下五个值的转换结果为false,其他的值全部为true。
undefinednull0(包含-0和+0)NaN''(空字符串)
1 | |
当然,true和false这两个布尔值不会发生变化
1 | |
注意,所有对象(包括空对象)的转换结果都是true,甚至连false对应的布尔对象new Boolean(false)也是true
1 | |
所有对象的布尔值都是true,这是因为 Javascript 语言设计的时候,出于性能的考虑,如果对象需要计算才能得到布尔值,对于obj1 && obj2这样的场景,可能会需要较多的计算
为了保证性能,就统一规定,对象的布尔值为true
自动转换
下面介绍自动转换,它是以强制转换为基础的
遇到以下三种情况时,JavaScript 会自动转换数据类型,即转换是自动完成的,用户不可见
- 不同类型的数据互相运算
1 | |
- 对非布尔值类型的数据求布尔值
1 | |
- 对非数值类型的值使用一元运算符(即
+和-)
1 | |
自动转换的规则是这样的:预期什么类型的值,就调用该类型的转换函数
比如,某个位置预期为字符串,就调用String()函数进行转换。如果该位置既可以是字符串,也可能是数值,那么默认转为数值
由于自动转换具有不确定性,而且不易除错,建议在预期为布尔值、数值、字符串的地方,全部使用Boolean()、Number()和String()函数进行显式转换。
自动转换为布尔值
Javascript 遇到预期为布尔值的地方(比如if语句的条件部分),就会将非布尔值的参数自动转换为布尔值。系统内部会自动调用Boolean()函数
因此除了以下五个值,其他都是自动转为true
undefinednull+0或-0NaN''(空字符串)
下面这个例子中,条件部分的每个值都相当于false,使用否定运算符后,就变成了true
1 | |
下面两种写法,有时也用于将一个表达式转为布尔值。它们内部调用的也是Boolean()函数
1 | |
自动转换为字符串
Javascript 遇到预期为字符串的地方,就会将非字符串的值自动转为字符串
具体规则是,先将复合类型的值转为原始类型的值,再将原始类型的值转为字符串
字符串的自动转换,主要发生在字符串的加法运算时。当一个值为字符串,另一个值为非字符串,则后者转为字符串
1 | |
这种自动转换很容易出错。
1 | |
上面代码中,开发者可能期望返回120,但是由于自动转换,实际上返回了一个字符10020
自动转换为数值
Javascript 遇到预期为数值的地方,就会将参数值自动转换为数值
系统内部会自动调用Number()函数。
除了加法运算符(+)有可能把运算子转为字符串,其他运算符都会把运算子自动转成数值
1 | |
上面代码中,运算符两侧的运算子,都被转成了数值
注意:
null转为数值时为0,而undefined转为数值时为NaN
一元运算符也会把运算子转成数值
1 | |
错误处理机制
Error 实例对象
JavaScript 解析或运行时,一旦发生错误,引擎就会抛出一个错误对象
Javascript 原生提供Error构造函数,所有抛出的错误都是这个构造函数的实例
1 | |
上面代码中,我们调用Error构造函数,生成一个实例对象err
Error构造函数接受一个参数,表示错误提示,可以从实例的message属性读到这个参数
抛出Error实例对象以后,整个程序就中断在发生错误的地方,不再往下执行
Javascript 语言标准只提到,Error实例对象必须有message属性,表示出错时的提示信息,没有提到其他属性
大多数 Javascript 引擎,对Error实例还提供name和stack属性,分别表示错误的名称和错误的堆栈,但它们是非标准的,不是每种实现都有
- message:错误提示信息
- name:错误名称(非标准属性)
- stack:错误的堆栈(非标准属性)
使用name和message这两个属性,可以对发生什么错误有一个大概的了解
1 | |
stack属性用来查看错误发生时的堆栈。
1 | |
上面代码中,错误堆栈的最内层是throwit函数,然后是catchit函数,最后是函数的运行环境
原生错误类型
Error实例对象是最一般的错误类型,在它的基础上,Javascript 还定义了其他6种错误对象
也就是说,存在Error的6个派生对象
SyntaxError 对象
SyntaxError对象是解析代码时发生的语法错误
1 | |
上面代码的错误,都是在语法解析阶段就可以发现,所以会抛出SyntaxError。第一个错误提示是“token 非法”,第二个错误提示是“字符串不符合要求”
ReferenceError 对象
ReferenceError对象是引用一个不存在的变量时发生的错误
1 | |
另一种触发场景是,将一个值分配给无法分配的对象,比如对函数的运行结果赋值
1 | |
上面代码对函数console.log的运行结果赋值,结果引发了ReferenceError错误
RangeError 对象
RangeError对象是一个值超出有效范围时发生的错误。主要有几种情况,一是数组长度为负数,二是Number对象的方法参数超出范围,以及函数堆栈超过最大值
1 | |
TypeError 对象
TypeError对象是变量或参数不是预期类型时发生的错误
比如,对字符串、布尔值、数值等原始类型的值使用new命令,就会抛出这种错误,因为new命令的参数应该是一个构造函数
1 | |
上面代码的第二种情况,调用对象不存在的方法,也会抛出TypeError错误,因为obj.unknownMethod的值是undefined,而不是一个函数
URIError 对象
URIError对象是 URI 相关函数的参数不正确时抛出的错误,主要涉及encodeURI()、decodeURI()、encodeURIComponent()、decodeURIComponent()、escape()和unescape()这六个函数
1 | |
EvalError 对象
eval函数没有被正确执行时,会抛出EvalError错误。该错误类型已经不再使用了,只是为了保证与以前代码兼容,才继续保留
总结
以上这6种派生错误,连同原始的Error对象,都是构造函数。开发者可以使用它们,手动生成错误对象的实例。这些构造函数都接受一个参数,代表错误提示信息(message)
1 | |
自定义错误
除了 JavaScript 原生提供的七种错误对象,还可以定义自己的错误对象
1 | |
上面代码自定义一个错误对象UserError,让它继承Error对象。然后,就可以生成这种自定义类型的错误了
1 | |
throw 语句
throw语句的作用是手动中断程序执行,抛出一个错误
1 | |
上面代码中,如果变量x小于等于0,就手动抛出一个错误,告诉用户x的值不正确,整个程序就会在这里中断执行。可以看到,throw抛出的错误就是它的参数,这里是一个Error实例
throw也可以抛出自定义错误
1 | |
上面代码中,throw抛出的是一个UserError实例
实际上,throw可以抛出任何类型的值。也就是说,它的参数可以是任何值
1 | |
对于 Javascript 引擎来说,遇到throw语句,程序就中止了。引擎会接收到throw抛出的信息,可能是一个错误实例,也可能是其他类型的值
try…catch 结构
一旦发生错误,程序就中止执行了
Javascript 提供了try...catch结构,允许对错误进行处理,选择是否往下执行
1 | |
上面代码中,try代码块抛出错误(上例用的是throw语句),Javascript 引擎就立即把代码的执行,转到catch代码块,或者说错误被catch代码块捕获了。catch接受一个参数,表示try代码块抛出的值
如果你不确定某些代码是否会报错,就可以把它们放在try...catch代码块之中,便于进一步对错误进行处理
1 | |
上面代码中,如果函数f执行报错,就会进行catch代码块,接着对错误进行处理
catch代码块捕获错误之后,程序不会中断,会按照正常流程继续执行下去
1 | |
上面代码中,try代码块抛出的错误,被catch代码块捕获后,程序会继续向下执行
catch代码块之中,还可以再抛出错误,甚至使用嵌套的try...catch结构
1 | |
上面代码中,catch代码之中又抛出了一个错误
为了捕捉不同类型的错误,catch代码块之中可以加入判断语句
1 | |
上面代码中,catch捕获错误之后,会判断错误类型(EvalError还是RangeError),进行不同的处理
finally 代码块
try...catch结构允许在最后添加一个finally代码块,表示不管是否出现错误,都必需在最后运行的语句
1 | |
上面代码中,由于没有catch语句块,一旦发生错误,代码就会中断执行。中断执行之前,会先执行finally代码块,然后再向用户提示报错信息
1 | |
上面代码中,try代码块没有发生错误,而且里面还包括return语句,但是finally代码块依然会执行。而且,这个函数的返回值还是result
下面的例子说明,return语句的执行是排在finally代码之前,只是等finally代码执行完毕后才返回
1 | |
上面代码说明,return语句里面的count的值,是在finally代码块运行之前就获取了
下面是finally代码块用法的典型场景
1 | |
上面代码首先打开一个文件,然后在try代码块中写入文件,如果没有发生错误,则运行finally代码块关闭文件;一旦发生错误,则先使用catch代码块处理错误,再使用finally代码块关闭文件
下面的例子充分反映了try...catch...finally这三者之间的执行顺序
1 | |
上面代码中,catch代码块结束执行之前,会先执行finally代码块
catch代码块之中,触发转入finally代码块的标志,不仅有return语句,还有throw语句
1 | |
上面代码中,进入catch代码块之后,一遇到throw语句,就会去执行finally代码块,其中有return false语句,因此就直接返回了,不再会回去执行catch代码块剩下的部分了
try代码块内部,还可以再使用try代码块
1 | |
上面代码中,try里面还有一个try。内层的try报错(console拼错了),这时会执行内层的finally代码块,然后抛出错误,被外层的catch捕获
编程风格
概述
“编程风格”(programming style)指的是编写代码的样式规则。不同的程序员,往往有不同的编程风格
有人说,编译器的规范叫做“语法规则”(grammar),这是程序员必须遵守的;而编译器忽略的部分,就叫“编程风格”(programming style),这是程序员可以自由选择的。这种说法不完全正确,程序员固然可以自由选择编程风格,但是好的编程风格有助于写出质量更高、错误更少、更易于维护的程序
所以,编程风格的选择不应该基于个人爱好、熟悉程度、打字量等因素,而要考虑如何尽量使代码清晰易读、减少出错。你选择的,不是你喜欢的风格,而是一种能够清晰表达你的意图的风格。这一点,对于 Javascript 这种语法自由度很高的语言尤其重要
必须牢记的一点是,如果你选定了一种“编程风格”,就应该坚持遵守,切忌多种风格混用。如果你加入他人的项目,就应该遵守现有的风格
缩进
行首的空格和 Tab 键,都可以产生代码缩进效果(indent)
Tab 键可以节省击键次数,但不同的文本编辑器对 Tab 的显示不尽相同,有的显示四个空格,有的显示两个空格,所以有人觉得,空格键可以使得显示效果更统一
无论你选择哪一种方法,都是可以接受的,要做的就是始终坚持这一种选择。不要一会使用 Tab 键,一会使用空格键
区块
如果循环和判断的代码体只有一行,Javascript 允许该区块(block)省略大括号
1 | |
上面代码的原意可能是下面这样。
1 | |
但是,实际效果却是下面这样。
1 | |
因此,建议总是使用大括号表示区块
另外,区块起首的大括号的位置,有许多不同的写法。最流行的有两种,一种是起首的大括号另起一行。
1 | |
另一种是起首的大括号跟在关键字的后面。
1 | |
一般来说,这两种写法都可以接受。但是,Javascript 要使用后一种,因为 Javascript 会自动添加句末的分号,导致一些难以察觉的错误
1 | |
上面的代码的原意,是要返回一个对象,但实际上返回的是undefined,因为 JavaScript 自动在return语句后面添加了分号。为了避免这一类错误,需要写成下面这样
1 | |
因此,表示区块起首的大括号,不要另起一行
圆括号
圆括号(parentheses)在 Javascript 中有两种作用,一种表示函数的调用,另一种表示表达式的组合(grouping)
1 | |
建议可以用空格,区分这两种不同的括号
表示函数调用时,函数名与左括号之间没有空格。
表示函数定义时,函数名与左括号之间没有空格。
其他情况时,前面位置的语法元素与左括号之间,都有一个空格。
按照上面的规则,下面的写法都是不规范的
1 | |
上面代码的最后一行是一个匿名函数,function是语法关键字,不是函数名,所以与左括号之间应该要有一个空格
行尾的分号
分号表示一条语句的结束。Javascript 允许省略行尾的分号
事实上,确实有一些开发者行尾从来不写分号。但是,由于下面要讨论的原因,建议还是不要省略这个分号
不使用分号的情况
首先,以下三种情况,语法规定本来就不需要在结尾添加分号
(1)for 和 while 循环
1 | |
注意,do...while循环是有分号的
1 | |
(2)分支语句:if,switch,try
1 | |
(3)函数的声明语句
1 | |
注意,函数表达式仍然要使用分号
1 | |
以上三种情况,如果使用了分号,并不会出错。因为,解释引擎会把这个分号解释为空语句
分号的自动添加
除了上一节的三种情况,所有语句都应该使用分号
但是,如果没有使用分号,大多数情况下,Javascript 会自动添加
1 | |
这种语法特性被称为“分号的自动添加”(Automatic Semicolon Insertion,简称 ASI)
因此,有人提倡省略句尾的分号。麻烦的是,如果下一行的开始可以与本行的结尾连在一起解释,Javascript 就不会自动添加分号
1 | |
上面代码都会多行放在一起解释,不会每一行自动添加分号。这些例子还是比较容易看出来的,但是下面这个例子就不那么容易看出来了
1 | |
下面是更多不会自动添加分号的例子
1 | |
只有下一行的开始与本行的结尾,无法放在一起解释,Javascript 引擎才会自动添加分号
1 | |
另外,如果一行的起首是“自增”(++)或“自减”(--)运算符,则它们的前面会自动添加分号
1 | |
上面代码之所以会得到1 2 0的结果,原因是自增和自减运算符前,自动加上了分号。上面的代码实际上等同于下面的形式
1 | |
如果continue、break、return和throw这四个语句后面,直接跟换行符,则会自动添加分号
这意味着,如果return语句返回的是一个对象的字面量,起首的大括号一定要写在同一行,否则得不到预期结果。
1 | |
由于解释引擎自动添加分号的行为难以预测,因此编写代码的时候不应该省略行尾的分号
不应该省略结尾的分号,还有一个原因。有些 Javascript 代码压缩器(uglifier)不会自动添加分号,因此遇到没有分号的结尾,就会让代码保持原状,而不是压缩成一行,使得压缩无法得到最优的结果
另外,不写结尾的分号,可能会导致脚本合并出错。所以,有的代码库在第一行语句开始前,会加上一个分号
1 | |
上面这种写法就可以避免与其他脚本合并时,排在前面的脚本最后一行语句没有分号,导致运行出错的问题。
全局变量
JavaScript 最大的语法缺点,可能就是全局变量对于任何一个代码块,都是可读可写。这对代码的模块化和重复使用,非常不利
因此,建议避免使用全局变量。如果不得不使用,可以考虑用大写字母表示变量名,这样更容易看出这是全局变量,比如UPPER_CASE
变量声明
Javascript 会自动将变量声明“提升”(hoist)到代码块(block)的头部
1 | |
这意味着,变量x是if代码块之前就存在了。为了避免可能出现的问题,最好把变量声明都放在代码块的头部
1 | |
上面这样的写法,就容易看出存在一个全局的循环变量i
另外,所有函数都应该在使用之前定义。函数内部的变量声明,都应该放在函数的头部
with 语句
with可以减少代码的书写,但是会造成混淆
1 | |
上面的代码,可以有四种运行结果:
1 | |
这四种结果都可能发生,取决于不同的变量是否有定义。因此,不要使用with语句
相等和严格相等
JavaScript 有两个表示相等的运算符:“相等”(==)和“严格相等”(===)
相等运算符会自动转换变量类型,造成很多意想不到的情况
1 | |
因此,建议不要使用相等运算符(==),只使用严格相等运算符(===)
语句的合并
有些程序员追求简洁,喜欢合并不同目的的语句。比如,原来的语句是
1 | |
他喜欢写成下面这样。
1 | |
虽然语句少了一行,但是可读性大打折扣,而且会造成误读,让别人误解这行代码的意思是下面这样
1 | |
建议不要将不同目的的语句,合并成一行
自增和自减运算符
自增(++)和自减(--)运算符,放在变量的前面或后面,返回的值不一样,很容易发生错误。事实上,所有的++运算符都可以用+= 1代替
1 | |
改用+= 1,代码变得更清晰了
建议自增(++)和自减(--)运算符尽量使用+=和-=代替
switch…case 结构
switch...case结构要求,在每一个case的最后一行必须是break语句,否则会接着运行下一个case。这样不仅容易忘记,还会造成代码的冗长
而且,switch...case不使用大括号,不利于代码形式的统一
此外,这种结构类似于goto语句,容易造成程序流程的混乱,使得代码结构混乱不堪,不符合面向对象编程的原则
1 | |
上面的代码建议改写成对象结构。
1 | |
因此,建议switch...case结构可以用对象结构代替
console 对象与控制台
console 对象
console对象是 Javascript 的原生对象,它有点像 Unix 系统的标准输出stdout和标准错误stderr,可以输出各种信息到控制台,并且还提供了很多有用的辅助方法
console的常见用途有两个
- 调试程序,显示网页代码运行时的错误信息
- 提供了一个命令行接口,用来与网页代码互动
console 对象的静态方法
console对象提供的各种静态方法,用来与控制台窗口互动
console.log(),console.info(),console.debug()
console.log方法用于在控制台输出信息。它可以接受一个或多个参数,将它们连接起来输出
1 | |
console.log方法会自动在每次输出的结尾,添加换行符。
1 | |
如果第一个参数是格式字符串(使用了格式占位符),console.log方法将依次用后面的参数替换占位符,然后再进行输出
1 | |
上面代码中,console.log方法的第一个参数有三个占位符(%s),第二、三、四个参数会在显示时,依次替换掉这个三个占位符
console.log方法支持以下占位符,不同类型的数据必须使用对应的占位符
%s字符串%d整数%i整数%f浮点数%o对象的链接%cCSS 格式字符串
1 | |
上面代码中,第二个参数是数值,对应的占位符是%d,第三个参数是字符串,对应的占位符是%s
使用%c占位符时,对应的参数必须是 CSS 代码,用来对输出内容进行 CSS 渲染
1 | |
上面代码运行后,输出的内容将显示为黄底红字
console.log方法的两种参数格式,可以结合在一起使用
1 | |
如果参数是一个对象,console.log会显示该对象的值
1 | |
上面代码输出Date对象的值,结果为一个构造函数
console.info是console.log方法的别名,用法完全一样。只不过console.info方法会在输出信息的前面,加上一个蓝色图标
console.debug方法与console.log方法类似,会在控制台输出调试信息。但是,默认情况下,console.debug输出的信息不会显示,只有在打开显示级别在verbose的情况下,才会显示
console对象的所有方法,都可以被覆盖。因此,可以按照自己的需要,定义console.log方法
1 | |
上面代码表示,使用自定义的console.log方法,可以在显示结果添加当前时间
console.warn(),console.error()
warn方法和error方法也是在控制台输出信息,它们与log方法的不同之处在于,warn方法输出信息时,在最前面加一个黄色三角,表示警告;error方法输出信息时,在最前面加一个红色的叉,表示出错。同时,还会高亮显示输出文字和错误发生的堆栈。其他方面都一样
1 | |
可以这样理解,log方法是写入标准输出(stdout),warn方法和error方法是写入标准错误(stderr)
console.table()
对于某些复合类型的数据,console.table方法可以将其转为表格显示
1 | |
上面代码的language变量,转为表格显示如下
| (index) | name | fileExtension |
|---|---|---|
| 0 | “JavaScript” | “.js” |
| 1 | “TypeScript” | “.ts” |
| 2 | “CoffeeScript” | “.coffee” |
下面是显示表格内容的例子
1 | |
上面代码的language,转为表格显示如下
| (index) | name | paradigm |
|---|---|---|
| csharp | “C#” | “object-oriented” |
| fsharp | “F#” | “functional” |
console.count()
count方法用于计数,输出它被调用了多少次
1 | |
上面代码每次调用greet函数,内部的console.count方法就输出执行次数
该方法可以接受一个字符串作为参数,作为标签,对执行次数进行分类
1 | |
上面代码根据参数的不同,显示bob执行了两次,alice执行了一次
console.dir(),console.dirxml()
dir方法用来对一个对象进行检查(inspect),并以易于阅读和打印的格式显示
1 | |
上面代码显示dir方法的输出结果,比log方法更易读,信息也更丰富
该方法对于输出 DOM 对象非常有用,因为会显示 DOM 对象的所有属性
1 | |
Node 环境之中,还可以指定以代码高亮的形式输出
1 | |
dirxml方法主要用于以目录树的形式,显示 DOM 节点
1 | |
如果参数不是 DOM 节点,而是普通的 JavaScript 对象,console.dirxml等同于console.dir
1 | |
console.assert()
console.assert方法主要用于程序运行过程中,进行条件判断,如果不满足条件,就显示一个错误,但不会中断程序执行。这样就相当于提示用户,内部状态不正确
它接受两个参数,第一个参数是表达式,第二个参数是字符串。只有当第一个参数为false,才会提示有错误,在控制台输出第二个参数,否则不会有任何结果
1 | |
下面是一个例子,判断子节点的个数是否大于等于500
1 | |
上面代码中,如果符合条件的节点小于500个,不会有任何输出;只有大于等于500时,才会在控制台提示错误,并且显示指定文本
console.time(),console.timeEnd()
这两个方法用于计时,可以算出一个操作所花费的准确时间
1 | |
time方法表示计时开始,timeEnd方法表示计时结束。它们的参数是计时器的名称。调用timeEnd方法之后,控制台会显示“计时器名称: 所耗费的时间”
console.group(),console.groupEnd(),console.groupCollapsed()
console.group和console.groupEnd这两个方法用于将显示的信息分组
它只在输出大量信息时有用,分在一组的信息,可以用鼠标折叠/展开
1 | |
上面代码会将“二级分组”显示在“一级分组”内部,并且“一级分组”和“二级分组”前面都有一个折叠符号,可以用来折叠本级的内容
console.groupCollapsed方法与console.group方法很类似,唯一的区别是该组的内容,在第一次显示时是收起的(collapsed),而不是展开的
1 | |
上面代码只显示一行”Fetching Data“,点击后才会展开,显示其中包含的两行
console.trace(),console.clear()
console.trace方法显示当前执行的代码在堆栈中的调用路径。
1 | |
console.clear方法用于清除当前控制台的所有输出,将光标回置到第一行。如果用户选中了控制台的“Preserve log”选项,console.clear方法将不起作用
控制台命令行 API
浏览器控制台中,除了使用console对象,还可以使用一些控制台自带的命令行方法
(1)$_
$_属性返回上一个表达式的值。
1 | |
(2)$0 - $4
控制台保存了最近5个在 Elements 面板选中的 DOM 元素,$0代表倒数第一个(最近一个),$1代表倒数第二个,以此类推直到$4。
(3)$(selector)
$(selector)返回第一个匹配的元素,等同于document.querySelector()。注意,如果页面脚本对$有定义,则会覆盖原始的定义。比如,页面里面有 jQuery,控制台执行$(selector)就会采用 jQuery 的实现,返回一个数组。
(4)$$(selector)
$$(selector)返回选中的 DOM 对象,等同于document.querySelectorAll。
(5)$x(path)
$x(path)方法返回一个数组,包含匹配特定 XPath 表达式的所有 DOM 元素。
1 | |
上面代码返回所有包含a元素的p元素。
(6)inspect(object)
inspect(object)方法打开相关面板,并选中相应的元素,显示它的细节。DOM 元素在Elements面板中显示,比如inspect(document)会在 Elements 面板显示document元素。JavaScript 对象在控制台面板Profiles面板中显示,比如inspect(window)。
(7)getEventListeners(object)
getEventListeners(object)方法返回一个对象,该对象的成员为object登记了回调函数的各种事件(比如click或keydown),每个事件对应一个数组,数组的成员为该事件的回调函数。
(8)keys(object),values(object)
keys(object)方法返回一个数组,包含object的所有键名。
values(object)方法返回一个数组,包含object的所有键值。
1 | |
(9)monitorEvents(object[, events]) ,unmonitorEvents(object[, events])
monitorEvents(object[, events])方法监听特定对象上发生的特定事件。事件发生时,会返回一个Event对象,包含该事件的相关信息。unmonitorEvents方法用于停止监听。
1 | |
上面代码分别表示单个事件和多个事件的监听方法。
1 | |
上面代码表示如何停止监听。
monitorEvents允许监听同一大类的事件。所有事件可以分成四个大类。
- mouse:”mousedown”, “mouseup”, “click”, “dblclick”, “mousemove”, “mouseover”, “mouseout”, “mousewheel”
- key:”keydown”, “keyup”, “keypress”, “textInput”
- touch:”touchstart”, “touchmove”, “touchend”, “touchcancel”
- control:”resize”, “scroll”, “zoom”, “focus”, “blur”, “select”, “change”, “submit”, “reset”
1 | |
上面代码表示监听所有key大类的事件。
(10)其他方法
命令行 API 还提供以下方法。
clear():清除控制台的历史。copy(object):复制特定 DOM 元素到剪贴板。dir(object):显示特定对象的所有属性,是console.dir方法的别名。dirxml(object):显示特定对象的 XML 形式,是console.dirxml方法的别名。
debugger 语句
debugger语句主要用于除错,作用是设置断点。如果有正在运行的除错工具,程序运行到debugger语句时会自动停下。如果没有除错工具,debugger语句不会产生任何结果,Javascript 引擎自动跳过这一句
Chrome 浏览器中,当代码运行到debugger语句时,就会暂停运行,自动打开脚本源码界面
1 | |
上面代码打印出0,1,2以后,就会暂停,自动打开源码界面,等待进一步处理
Javascript进阶
事件循环 Event Loop
线程与进程
- 进程是cpu资源分配的最小单位(系统会给它分配内存)
- 不同的进程之间是可以同学的,如管道、FIFO(命名管道)、消息队列
- 一个进程里有单个或多个线程
- 浏览器是多进程的,因为系统给它的进程分配了资源(cpu、内存)(打开Chrome会有一个主进程,每打开一个Tab页就有一个独立的进程)
浏览器的渲染进程是多线程的
- GUI渲染线程
- JS引擎线程
- 事件触发线程
- 定时触发器线程
- 异步HTTP请求线程
事件循环机制
实际上是描述了一些函数处理顺序和过程
参考:https://www.bilibili.com/video/bv1kf4y1U7Ln
原型链
原型
现在有1个类A,我想要创建一个类B,这个类是以A为原型的,并且能进行扩展。我们称B的原型为A
原型关系
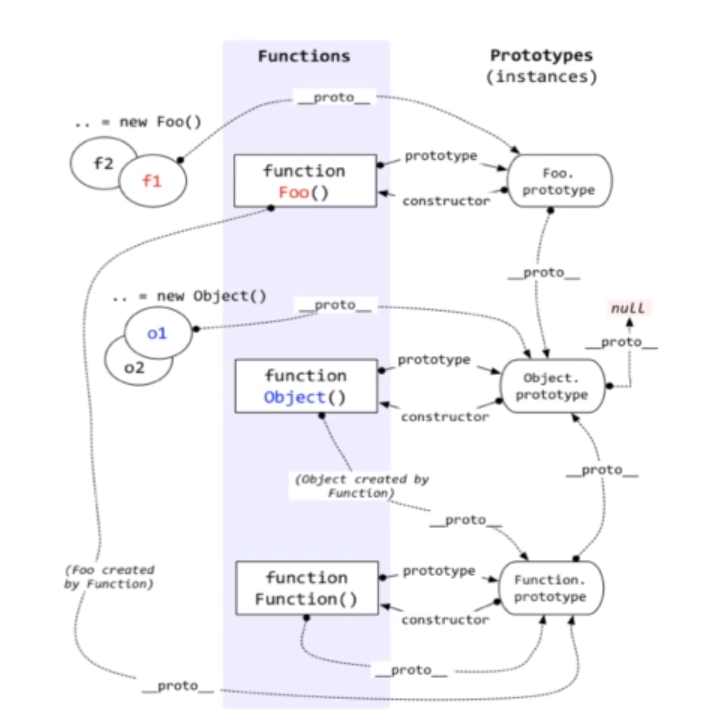
1 | |
.prototype
返回原型对象的引用__proto__ (实际上是[[prototype]],不过浏览器里一般都简写)
这个属性保存着原型对象的属性Object是所有对象的“老祖宗”,所有的__proto__最终都会指向Object,Object本身并没有__proto__属性
1
a.__proto__ = A.prototype;constructor
A原型的属性,指向A
参考:https://www.bilibili.com/video/BV117411v76o
原型链
参考:https://www.bilibili.com/video/BV1N7411k7D2
异步编程
promise
参考:https://www.bilibili.com/video/BV15J411G7FG?from=search&seid=7940074723107809573
跨域
客户端与不同源服务端的通信
- CORS
跨域资源共享,解决跨域请求的成熟方案 - JSONP
基于<script>标签,具有可跨域特性
只能用于GET请求 - iframe
通过<iframe>标签在同一个页面暂时不同源的页面
通过PostMessage进行页面间的通信 - 反向代理
通过反向代理让客户端与服务端保持同步,较为安全
Webpack 打包
目的:将不同类型的源文件编译打包成静态文件
- 前端技术纷繁复杂,缺乏统一管理
- 大型项目需要模块化
- 对于JSX,TS之类的新技术,需要编译以后才能使用
编译器,插件,优化
参考:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!