Javascript-混淆
本文最后更新于:2021年3月23日 晚上
信息
代码混淆是增加静态分析难度而牺牲运行效率的一种方法
难以分析是混淆的目的,在能达到目的的同时需要确保混淆后的代码和源代码功能表现一致
混淆分类
对于混淆的分类,普遍以 Collberg 的理论为基础分为:
布局混淆(Layout obfuscation)、数据混淆(data obfuscation)、控制混淆(Control obfuscation)、预防混淆(Preventive obfuscation)
布局混淆
布局混淆指删除或混淆与执行无关的辅助文本信息
具体指源代码中的注释文本,调试信息等
删除无效代码
- 注释文本
详细的注释文本对用户理解意义重大,生产环境就应删除 - 调试信息
调试代码在开发环境中对开发者调试Bug有极大帮助,生产环境就应该删除 - 无用函数和数据
在开发过程中,由于需求更改或重构无意遗留下来的内容,虽然未调试或使用,但被用于可以猜测开发者的意图和思路 - 缩进和换行符
Javascript 使用分号进行分局,所以删除代码缩进和换行符增加了阅读难度,也能大大减少代码体积。但这是可逆的,非常容易就能还原回去
标识符重命名
标识符(Identifier)一般指常量名,变量名,函数名。其字面意义可以帮助理解代码,所以要将标识符变为无意义的内容
1 | |
将变量名变成了无意义的内容。对于解释器来说,改更改不影响代码执行,也不会增加内存消耗
标识符重命名是少数几种没有明显副作用的混淆方法之一
常见处理方式:
- 单字母
将标识符重命名未单个简单字母很常见,因为这在处理的同时能压缩代码体积
需要注意的是,由于字母数量较少,可能会导致作用域内标识符重名碰撞(可以使用aa或者a2等稍微更复杂的方式解决) - 16进制字符
以_0x开头的随机16进数字结尾形式
优点在于形式相似,缺点在于标识符较长,会引起代码膨胀 - 相似结构
比如说用0、Q、o等组合出标识符,目的是为了不好辨认
可以合理设置长度,避免代码过度膨胀
这种做法关键在于:
- 作用域内避免标识符碰撞(重复)
- 尽量在不同作用域用多使用重复的标识符,以提升阅读难度
数据混淆
针对不同的数据类型可以对数据进行不同的混淆
数字混淆
进制转换
Javascript 除了常用的 十进制 标识形式外,还有 二进制、八进制、十六进制等表示形式。虽然看起来十分的不同(以0b,0,0x开头),但它们的机器码是等值的。但就理解而言,除了 十进制 ,其它的进制都并不好阅读
1 | |
浮点数并不支持这种类型的转换,因为操作系统底层存储其实并不存在小数,而十进制的小数形式只是迎合数学上的表达
大部分语言都不支持十进制以外的其它进制的小数表达式
浮点数虽然不能使用进制转换的方法进行混淆,但是 Javascript 支持科学计数法,可以使用科学计数法来进行简单的混淆
1 | |
效果并不怎么好
数学技巧
当数字型变量在代码中有一定的规律和作用范围,就可以通过数学技巧将它的表现形式转换未一种更难分析的形式
1 | |
通过 y = a * i + b 进行转换
1 | |
对比转换前后的代码,它们的语义是等价的,但是理解难度却大不相同
需要注意的是,转换前后数字所能表示的值会有所变化(如上代码将数字扩大8倍,会造成可表示的数少8倍),不要因为使用这个技巧使得数字超出可以表示的范围之外
数字拆解
对于数字而言,大多数时候可以通过 将字面量的数字以某种等价的公式拆分为表达式来提升代码分析难度
1 | |
根据勾股定理进行转换 5*5 = 4*4 +3*3
1 | |
其最重要的意义在于破坏语义,你无法直接看出他是在算时间
数字拆解与性能
拆分代码并不会降低运行效率
在浏览器引擎编译过程中会对代码进行优化,以 V8 引擎为例,遇到以上的代码会触发常量折叠优化策略,即在编译器里进行语法分析时,将常量进行计算求值,并用结果取代表达式,放入常量表
例如,在编译过程中i < 5*5*4会被转换为 i < 100
布尔混淆
布尔类型的取值范围比较固定而且范围非常小,javascript 隐式类型强转机制也使得对它混淆相对容易,手法也比较多
类型转换
类型转换 指一个值从一个类型隐式的转换到另一个类型的操作
1 | |
强制转换为 boolean 类型时,遵循规则:
- 特定值强制转换为 boolean 值为 false
undefinednullfalse+0、-0、NaN""
- 其它的一切值为 true
利用类型转换混淆boolean变量有很多方法,但为了避免代码膨胀,一般使用最简单的逻辑表达式!来进行
!undefined!null!0!NaN!""-
!{} -
![] -
!void(0)
构造随机数
可以利用乘法操作构造特定的随机数混淆布尔值
1 | |
generateNumber(true)会生成一个含有因数3而不含有因数5的整数generateNumber(false)会生成一个含有因数5而不含有因数3的整数
利用这个特点,在生成特定的随机数后,将布尔值替换成一个表达式,就可以隐藏原有值
1 | |
1 | |
布尔值大多数代码应用场景在代码控制流中,能让代码的控制流走向变得模糊,增加代码分析难度
字符串混淆
字符串往往包含一些重要的语义信息(比如密码错误提示)
可以运用一些方法将关键字符串分解成许多的片段,并将它们分散到程序的各个角落;进行异或操作等
Mealy机
Mealy机属于有限状态机的一种,它是基于当前状态和输入生成输出的有限状态自动机,这意味着它的状态图每条转移边都有输入和输出
与输出只依赖机器当前状态的摩根机有限状态机不同,它的输出与当前状态和输入都有关
次态 = f(现态, 输入)输出 = f(现态, 输入)根据 Mealy机 的特性,可以将字符串的每一个 bit位 和当前状态输入,输出实际的字符串
通过Mealy机对字符串 ‘mimi’ 和 ‘mila’ 进行加密
1 | |
实现 Mealy机 的方式有很多种,最简单的方式就是直接查询next表和out表
字符编码
Javascript 允许直接使用码点表示 Unicode 字符
1 | |
这对于机器来说没有区别,但对于人来说就变得不可阅读了
将代码中所有的字符串转变为 Unicode 会使得代码体积稍微变大一些,一般无关痛痒
如果只是单纯地转变,逆向也相对容易,在进行混淆时,可以选择一些一些不编码字符来增加逆向难度
1 | |
undefined 与 null 混淆
并不存在复杂的混淆方式,可以尝试利用语言特性进行混淆
1 | |
控制混淆
对程序的控制流进行变换,打乱的代码运行顺序会让代码阅读变得困难
控制混淆是一种效果较好的代码保护手段,但存在一定的混淆风险
不透明谓词
不透明谓词的逻辑来自于数理原理
通过严格的逻辑证明某些复杂的表达式成立,而这些成立的表达式成为不透明谓词表达式。表达式成立的结果是已知的,表达式结果表面上是不明显的,称为不透明
∀x,y, z∈Z, D>0, D=z² : x²-Dy²≠2
不透明谓词的模糊性和不透明性能够保护代码,在代码混淆中有广泛成熟的具体用途
假定源代码由 A与B 两块代码组成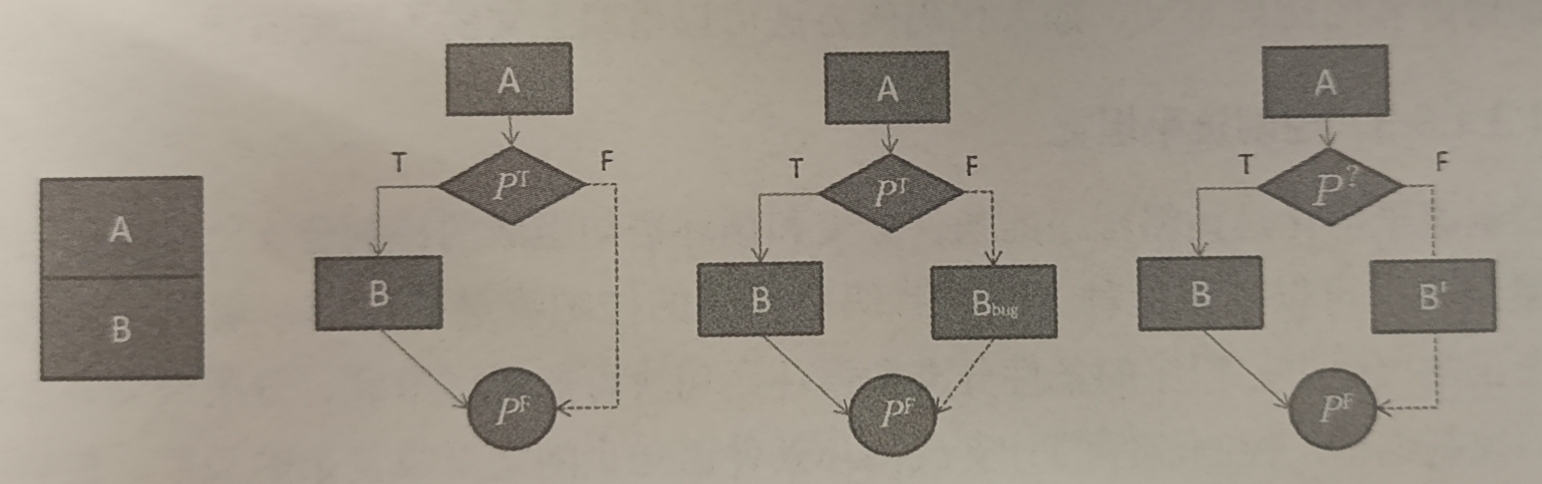
- 构造一个恒真不透明表达式 $ P^T $ 作为判断表达式插入
- 构造一个恒真不透明表达式 $ P^T $ 作为判断表达式插入,并且在结果为假的分支中插入存在BUG的代码
- 构造一个不确定真假的不透明谓词表达式 $ P^? $ ,构造一个和 B 作用相同,但形式不同代码 $ P^' $ 。因为 $ P^' $ 真假不定,所以对于攻击者而言,增加了一倍的阅读量
不透明谓词作为保护策略,理论上可以再代码的任何需要进行判断的位置中使用
要注意,复杂的不透明谓词会影响性能。因此应尽量选择再程序的核心算法或容易受到攻击的位置使用
插入冗余代码
冗余代码是指与程序中的其它代码没有任何调用关系的代码
死代码是指程序中永远执行不到的代码
将这些代码插入到程序中并不会对程序造成任何影响,同时可以增加代码阅读难度
插入代码的方法可以借助 不透明谓词的方式,直接插入非常容易就能去除
控制流平坦化
控制流平坦化是将程序的条件分支和循环语句组成的控制分支转化为单一的分发器结构
程序的条件分支和循环语句块可能通过串联、分层嵌套等形式形成复杂结构
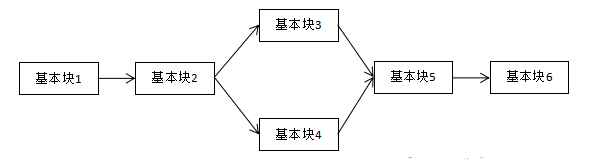
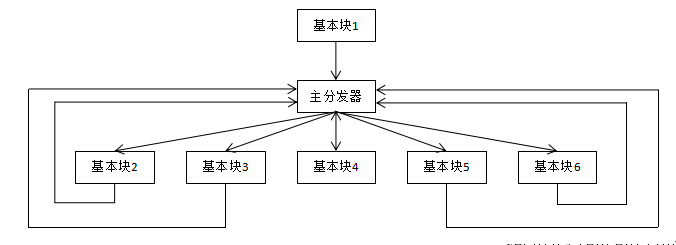
当所有代码都在同级,在阅读代码时旧无法线性阅读整个代码运行的逻辑流程,从而提升阅读难度
混淆前
1 | |
混淆后
1 | |
代码由 自上而下的线性流程 变成了 以switch控制分发平行代码块的结构
参考:
- 《风控要略 互联网业务反欺诈之路》
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!