消息队列-MessageQueue
本文最后更新于:2021年2月8日 下午
什么是消息队列
消息队列好比是一个存放消息的容器,发送者发送消息存到里面,当接收者需要消息的时候可以取出消息供自己使用
消息队列是分布式系统中重要的组件,使用消息队列主要是为了通过异步处理提高系统性能和削峰、降低系统耦合性
目前使用较多的消息队列有:ActiveMQ,RabbitMQ,Kafka,RocketMQ
队列 Queue 是一种先进先出的数据结构,所以消费消息时也是按照顺序来消费的
比如生产者发送消息1,2,3…对于消费者就会按照1,2,3…的顺序来消费
但是偶尔也会出现消息被消费的顺序不对的情况,比如某个消息消费失败又或者一个 queue 多个consumer 也会导致消息被消费的顺序不对,我们一定要保证消息被消费的顺序正确
除了上面说的消息消费顺序的问题,使用消息队列,我们还要考虑:如何保证消息不被重复消费?如何保证消息的可靠性传输(如何处理消息丢失的问题)?……等等问题
所以说使用消息队列也不是十全十美的,使用它也会让系统可用性降低、复杂度提高,另外需要我们保障一致性等问题
为什么要用消息队列
使用消息队列主要好处:
- 降低系统耦合
- 异步处理,提高系统性能
- 削峰,避免崩溃
解耦
假设现在有一个 可以产生userId的系统A 和 两个需要userId的系统,B和C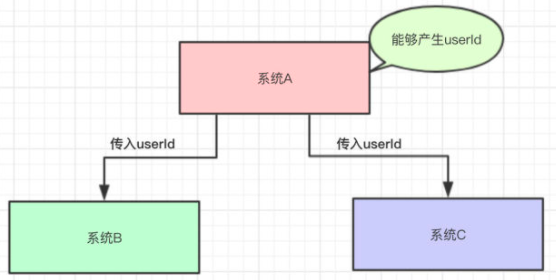
这样的结构下,代码会类似于
1 | |
此时,B与C系统都依赖于A
如果有一天,需要添加一个类似于B或C的系统D,那么A的代码需要修改
如果有一天,需要删除系统B或C,那么A的代码也需要更改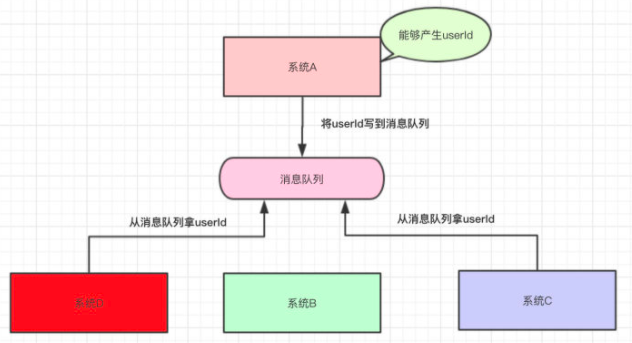
此时引入消息队列。系统A只专注于将 userId 写到消息队列中,系统C和D从消息队列中拿数据。此时,无论取userId 的系统发生什么更变,都不会影响到系统A。如此一来系统A与BC都解耦了
异步
类似的,假设现在有一个 可以产生userId的系统A 和 三个需要userId的系统,B、C和D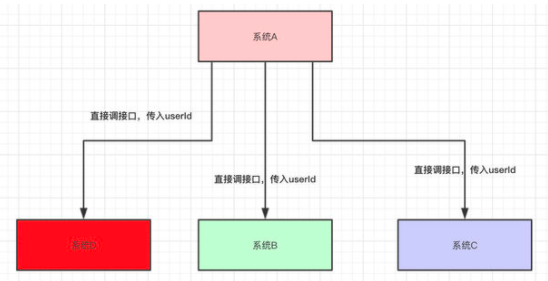
这样的结构下,代码会类似于
1 | |
这样的情况下会有一个问题,在 B,C、D 执行完毕之前,A就只能等待
这已经是 B、C、D 并行的情况,若是 B、C、D是串行的,那么等待的情况会更加糟糕
为了提高用户体验和吞吐量,其实可以用 消息队列 异步地调用系统 B、C、D 的接口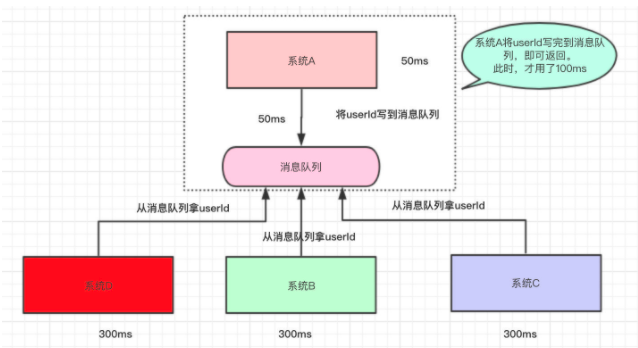
系统A执行完了以后,将 userId 写到消息队列中,然后就直接返回了(至于其他的操作,则异步处理)
消峰
这个其实非常好理解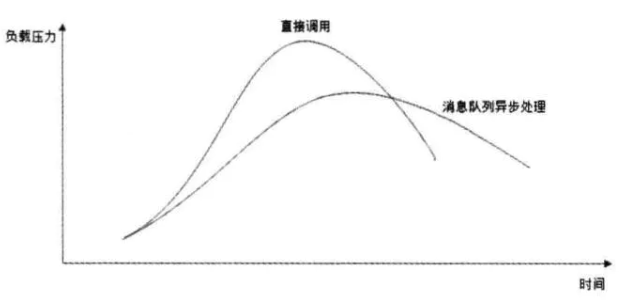
如果有一个A接口,1秒可以响应1000请求
此时外部调用A接口频率超过 1000次/s,那么不仅仅会导致接口响应缓慢,而且还有可能导致接口服务崩溃
此时在请求与接口间添加消息队列,将请求记录下来,等接口有空再去取,那么系统就会变得更加稳定
消息队列要点
高可用
无论是我们使用消息队列来做解耦、异步还是削峰,消息队列肯定不能是单机的
如果是单机的消息队列,万一这台机器挂了,那我们整个系统几乎就是不可用了
所以项目中使用消息队列,都是得集群/分布式的。要做集群/分布式就必然希望该消息队列能够提供现成的支持,而不是自己写代码手动去实现
数据丢失问题
我们将数据写到消息队列上,系统还没来得及取消息队列的数据,就挂掉了。此时如果没有做任何的措施,那么保存在队列中的数据就丢了
但如果做数据备份,那么备份到哪里?用什么方式?就是一个问题
常见MQ对比
ActiveMQ
社区算是比较成熟,但是较目前来说,ActiveMQ 的性能比较差,而且版本迭代很慢,不推荐使用RabbitMQ
在吞吐量方面虽然稍逊于 Kafka 和 RocketMQ ,但是由于它基于 erlang 开发,所以并发能力很强,性能极其好,延时很低,达到微秒级。但是也因为 RabbitMQ 基于 erlang 开发,所以国内很少有公司有实力做erlang源码级别的研究和定制。如果业务场景对并发量要求不是太高(十万级、百万级),那这四种消息队列中,RabbitMQ 一定是你的首选。如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范RocketMQ
阿里出品,Java 系开源项目,源代码我们可以直接阅读,然后可以定制自己公司的MQ,并且 RocketMQ 有阿里巴巴的实际业务场景的实战考验。RocketMQ 社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准 JMS 规范走的有些系统要迁移需要修改大量代码。还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用RocketMQ 挺好的kafka
的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms 级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时 kafka 最好是支撑较少的 topic 数量即可,保证其超高吞吐量。kafka 唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!