Scrapy-基础
本文最后更新于:2021年5月7日 下午
链接
官网:https://scrapy.org/
官方文档:https://docs.scrapy.org/en/latest/
信息
特点:入门快,扩展性强
内建CSS选择器和XPath表达式
基于IPython shell
Scrapy主要组件
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
运行流程
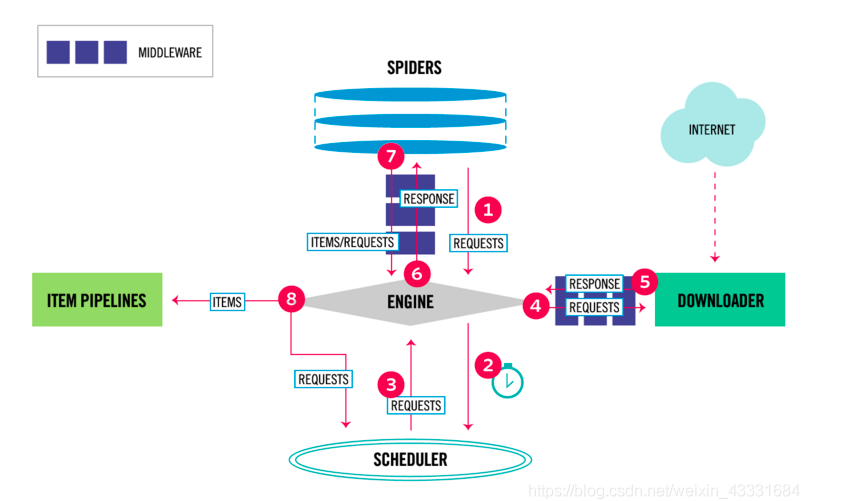
- Engine 从 Spider 中得到第一个Requests进行爬取
- ENGIN 将 Request 放入 SCHEDULER调度器,并且获取下个Request
- SCHEDULER 将 Requests 返回给ENGINE(因为ENGING进行任务调度)
- ENGINE 发送 Requests 到 Downoader,通过 Downloader Middlewares 进行处理(这一步进行Http请求,返回response)
- 通过 Downloader Middleware 进行资源下载(就是html信息),如果下载完成,通过 Dowloader 生成一个 Resonse 并且发送给 ENGINE
- ENGINE 从 DOWNLOADER 接收 Resonse, 并将 Resonse 发送给 Spider 进行处理。Spider 通过 Spider Middleware 进行处理 Response
- Spider 处理 Response 并且返回 items 和新的 Requests 给 ENGINE, 这部分处理通过 Spilder Middleware进行处理
- Engine 发送 items 到 item Pipelines 然后 发送 Request 到 Scheduler 并且 获取下个 Request 进行处理
- 重复第一个步骤进行处理。
基本代码流程
- 根据需要的数据项编写item
- 根据抓取要点编写spider与setting
- 编写pipeline以保存抓取的数据
基础操作
安装
1 | |
若是希望使用Scrapy shell的话,需要留意python环境变量的问题
创建项目
选定一个文件夹,打开控制台。输入指令
1 | |
命令会创建tutorial目录,并在里面生成一些文件
scrapy.cfg: 项目的配置文件tutorial/: 该项目的python模块。之后您将在此加入代码tutorial/items.py: 项目中的item文件tutorial/pipelines.py: 项目中的pipelines文件tutorial/settings.py: 项目的设置文件tutorial/spiders/: 放置spider代码的目录
定义Item
Item 是保存爬取到的数据的容器。
其使用方法和 python字典 类似, 并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
根据需要 爬取的网页 获取到的数据对Item进行建模。
1 | |
这里定义了一个Item 类,类中包含两个属性
编写Spider
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
1 | |
关于定义本身
为了创建一个Spider,您必须继承scrapy.spiders.Spider类, 且定义一些属性:name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。parse()是Spider的一个方法。 被调用时,每个 初始URL 完成下载后生成的Response对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的Request对象。
获取html中的数据
Scrapy使用基于XPath和CSS选择器的机制Scrapy Selectors来选取Html中的元素。Scrapy Selectors的四种基本方法- xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表 。
- css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表.
- extract(): 序列化该节点为unicode字符串并返回list。
- re(): 根据传入的正则表达式对数据进行提取,返回unicode字符串list列表。
如果想要记录整个编码后的网页可以这样做
1 | |
进行爬取
进入项目的根目录,执行下列命令启动Spider
1 | |
这里的 first 对应着Spider中定义的name
在控制台里你会看到一些详细的输出信息。
过程:
Scrapy为Spider的start_urls属性中的每个URL创建了scrapy.Request对象,并将parse方法作为回调函数(callback)赋值给了Request。- Request对象经过调度,执行生成
scrapy.http.Response对象并送回给Spider parse()方法。
保存数据
1 | |
该命令将采用JSON格式对爬取的数据进行序列化,生成 items.json 文件。
在类似本篇教程里这样小规模的项目中,这种存储方式已经足够。
如果需要对爬取到的item做更多更为复杂的操作,您可以编写 Item Pipeline 。
类似于我们在创建项目时对Item做的,用于编写自己的 tutorial/pipelines.py 也被创建。
不过如果仅仅想要保存item,您不需要实现任何的pipeline
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!