爬虫-基础
本文最后更新于:2021年1月25日 中午
HTML DOM
文档对象模型 中立于平台和语言的接口
允许程序动态地更新文档内容,结构和样式
js代码和css样式可以改变 HTML,但只是改变显示样式,并没有真正改变HTML文档本身
浏览器
页面渲染流程
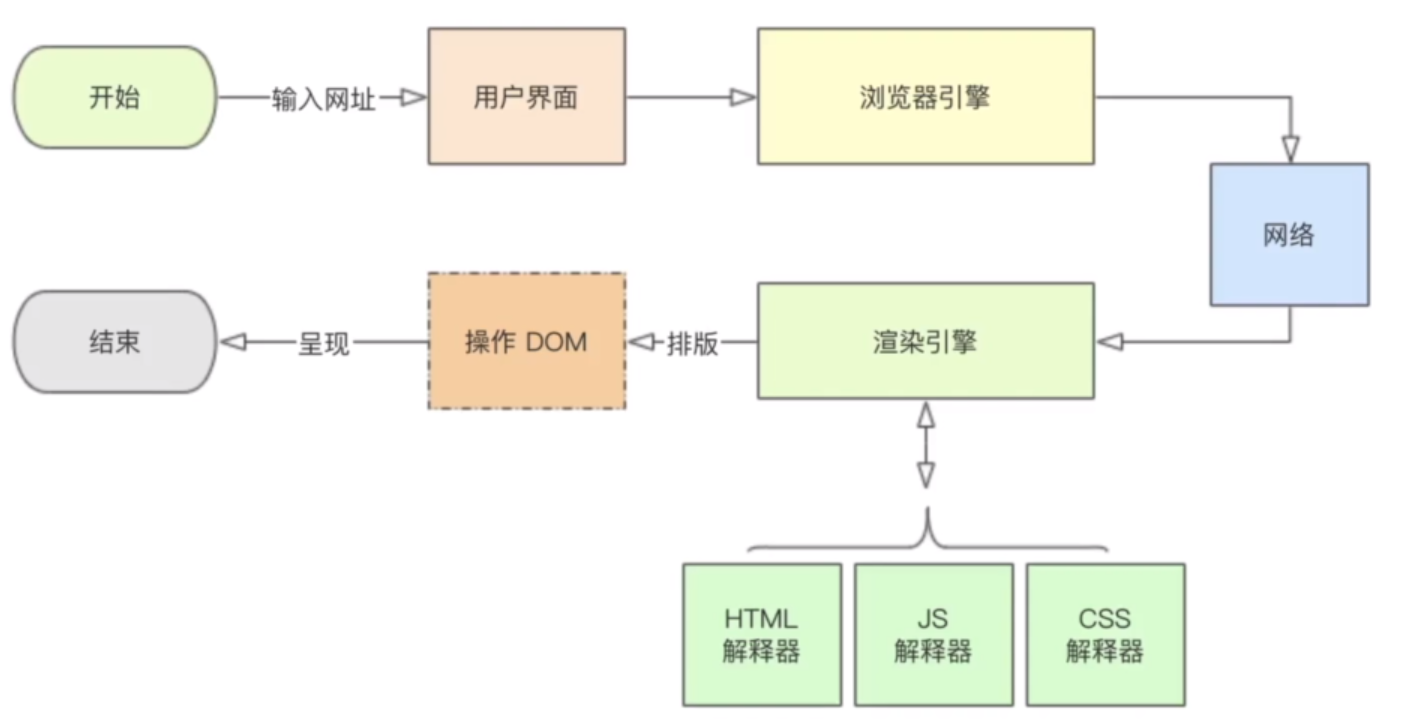
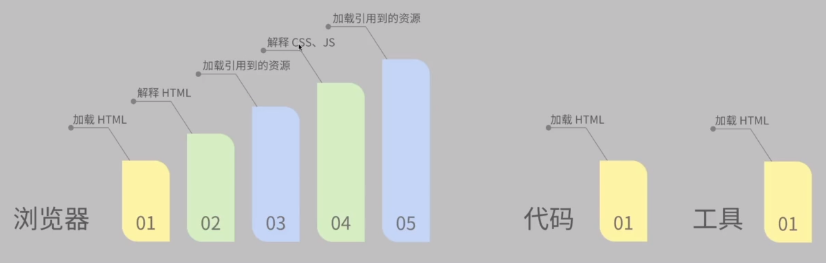
因为其它工具里没有js解释器,CSS解释器,所以可以通过这两个东西来进行反爬虫
浏览器缓存
- Cookies
用于服务端通信,存储量小 - Local Storage
存储量比Cookies大一些,只能存字符串 - Session Storage
只存在于当前Session,关闭浏览器就丢失 - IndexedDB
相当于浏览器上的SQL数据库,存储空间大,API较难掌握
HTTP与HTTPS
HTTP
Hyper Text Transfer Protocol
超文本传输协议,用于从网络传输超文本数据到本地浏览器的传送协议,能保证高效而准确的传送超文本文档(通常是网页html文件)
HTTPS
Hyper Text Transfer Protocol over Secure Socket Layer
以安全为目标的HTTP通道,即是在HTTP下加入SSL层,简称为HTTPS
简单来说就是更安全的HTTP
请求
请求一般分为四个部分:请求方法,请求url,请求头,请求体
请求方法
| 方法 | 描述 |
|---|---|
| GET | 请求指定的页面信息,并返回实体主体 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。 POST 请求可能会导致新的资源的建立和/或已有资源的修改 |
| HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容 |
| DELETE | 从客户端向服务器传送的数据取代指定的文档的内容 |
| CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器 |
| OPTIONS | 允许客户端查看服务器的性能 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断 |
| PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新 |
现在碰到的绝大部分请求都会是GET和POST请求
GET与POST的区别
- GET请求的参数 包含在URL中,POST并非在其中,而是会在请求体中通过表单的形式传递
- GET请求最多提交1024字节的数据,而POST则没有限制
请求头
| 常用信息 | 描述 |
|---|---|
| Accept | 请求头域,指定接受的内容类型 |
| Accept-Encoding | 指定接受的内容的编码格式 |
| Accept-Language | 指定接受的内容的语言 |
| Host | 指定服务器域名和TCP端口号,如果使用的是服务请求标准端口号,端口号可以省略 |
| Cookie | 网站为了辨识用户进行绘画跟踪而储存在用户本地的数据。主要功能是维持当前访问会话 |
| Referer | 用于标识请求从哪个页面发送过来,一般用于给服务器做数据统计 |
| User-Agent | 简称UA,标明用户使用的操作系统,浏览器信息 |
| Content-Type | 设置请求体的MIME类型,用于表示具体请求的媒体类型信息 |
| X-Requested-With | 标识Ajax请求,大部分js框架发送请求时都会设置它为XMLHttpRequest |
| Cache-Control | 设置请求响应链上所有的缓存机制必须遵守的指令 |
| Content-Length | 设置请求体的字节长度 |
| TE | 设置用户代理期望接受的传输编码格式,和响应头中的Transfer-Encoding字段一样 |
| DNT | 请求web应用禁用用户追踪 |
| Connection | 设置当前连接和hop-by-hop协议请求字段列表的控制选项 |
| Accept-Charset | 接受的字符编码 |
比较重要的信息:Cookies、Referer、User-Agent……
请求体
承载信息主体
响应
响应主要分为三个部分:响应状态码,响应头,响应体
响应状态码
标识请求是否已成功完成
响应分为五类:信息响应(100–199),成功响应(200–299),重定向(300–399),客户端错误(400–499)和服务器错误 (500–599)
详细:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status
响应头
| 常用信息 | 描述 |
|---|---|
| Date | 响应产生的时间 |
| Last-Modified | 文档的最后改动时间 |
| Allow | 服务器支持哪些请求方法 |
| Content-Encoding | 文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。 |
| Content-Length | 内容长度 |
| Content-Type | 表示后面的文档属于什么MIME类型 |
| Server | 服务器名字 |
| Expires | 响应过期时间,数据可以缓存在浏览器或者代理服务器中,如果再次访问,则可以从缓存中加载,降低服务器负荷 |
| Set-Cookie | 设置和页面关联的Cookie |
响应体
承载信息主体
会话
静态页面与动态页面
| 静态页面 | 动态页面 | |
|---|---|---|
| 内容 | 固定 | 可变 |
| 加载速度 | 快 | 慢 |
| 可维护性 | 差 | 好 |
| 动态页面可以解析URL中的参数变化,动态呈现不同的页面内容,更加灵活多变 |
无状态HTTP
无状态HTTP是指HTTP协议对事物处理是没有记忆能力的
向服务器发送请求,服务器解析请求,返回对应响应,这个过程是完全独立的,服务器不会记录前后状态的变化。这意味着如果你需要处理前面处理过的信息,则需要重传,会导致资源浪费
于是两个用于保持HTTP连接状态的技术出现了:会话 和 Cookies
会话
会话对象用来存储特定用户会话所需的属性和配置信息
当用户在Web页面中跳转时,存储在会话对象中的变量不会消失,会在整个用户会话中一直存在下去
当用户请求Web页时,如果用户还没有会话,Web服务器会自动创建一个会话对象。
当会话过期或被抛弃后,服务器将终止会话
Cookies
网站为了辨识用户身份、进行会话跟踪 存储在用户本地终端上的数据
会话维持
客户端第一次请求服务器时,服务器会返回一个相应头中带有Set-Cookie字段的响应给客户端用于标识用户,客户端则会将Cookies存起来
在浏览器再次请求该网站,浏览器会把此前存放的Cookies放到请求头里一起提交给服务器Cookies携带了会话ID信息,服务器检查就知道其对应的会话了
属性结构
| 属性 | 描述 |
|---|---|
| Name | Cookie名称 一旦创建,不可更改 |
| Value | Cookie值 如果为Unicode字符,则需要为字符编码 如果为二进制数据,则需要使用BASE64编码 |
| Domain | 可以访问该Cookie的域名 |
| Max Age | Cookie失效时间,单位为秒,常与Expires一同使用 若值为正数,则Cookie在Max Age秒后失效 若值为负数,则关闭浏览器后Cookie失效 |
| Path | Cookie使用路径 如果设置为/path/,则只有路径为/path/的页面才可以访问此Cookie 不设置则域名下所有页面均可访问此Cookie |
| Size 字段 | Cookie 大小 |
| HTTP 字段 | Cookie的httponly属性 若此属性为true,则只有HTTP头中会带有此Cookie信息,而不能通过document.cookie来访问此Cookie |
| Secure | 此Cookie是否只使用安全协议传输 |
会话Cookie与持久Cookie
会话Cookie 指那些被存在浏览器内存中的Cookie,关闭浏览器后该Cookie会失效
持久Cookie 指那些保存在客户端硬盘中的Cookie,下次使用浏览器还能用
很多时候,Cookie都会被设置为持久Cookie,而且设置一个相当长的失效时间,这样做可以节约登录的资源消耗
代理
服务商的服务器是为普通用户服务的,服务商并不想为爬虫的程序浪费资源,因此会想办法反爬虫
在你提交请求的时候,服务器会记录你的IP。当同一个IP在一段时间内访问频率远高于一个正常人操作的频率,那么想都不用想,这就是爬虫程序,他会将你的IP设置在黑名单里,不再接受你的请求
使用代理来伪装IP,让服务器以为你是来自不同的地方的用户,本机IP不超出阀值,就不会被封禁
基本原理
proxy server 代理服务器,功能是替代用户去获取网络信息,工作性质像是一个物流中转站
设置了代理以后,请求和响应都通过代理进行,服务器识别到的请求的IP是代理的IP
当代理足够多,将爬虫客户端高频率的请求分摊到多个代理服务器分别请求,形成很多看似合理的低频率访问,服务器就无法通过观察IP访问频率直接封禁IP来达到反爬虫的目的
需要注意的是 一个代理和客户端一样 会有访问频率过高而被封的可能,所以依然要注意访问频率
作用
- 突破IP访问限制
能访问到当前IP访问不了的站点 - 提高访问速度
通常代理服务器会设置一个较大的硬盘缓冲区,当有外界的信息通过时,会将它保存到缓冲区中。当其他用户访问相同的信息,可以从缓冲区里直接取出信息,提高访问速度 - 隐藏真实IP
保护自己或者,避免被封
类型
按照协议区分
| 代理类型 | 信息 | 协议默认端口 |
|---|---|---|
| FTP代理服务器 | 用户访问FTP服务,一般有上传、下载、缓存功能 | 21或2121 |
| HTTP代理服务器 | 用于访问网页,一般有内容过滤和缓存功能 | 80或8080或3128 |
| SSL/TLS代理 | 用于访问加密网站,一般有SSL或TLS加密功能 | 443 |
| RTSP 代理 | Real流媒体服务器,一般有缓存功能 | 554 |
| Telnet 代理 | 用于telnet远程控制(黑客入侵时常用于隐藏身份) | 23 |
| POP3/SMTP 代理 | POP3/SMTP收发右键,一般有缓存功能 | 110、25 |
| SOCKS 代理 | 只是单纯传递数据包,不关心协议和用法,速度较快,一般有缓存功能 | 1080 |
SOCKS代理分类
SOCKS4 SOCKS5 协议支持 TCP TCP/UDP 身份验证/域名解析 × √
按照匿名程度区分
| 代理类型 | 服务器获取到的IP信息 | 数据包改动 | 信息 |
|---|---|---|---|
| 高度匿名代理 | 代理服务器IP | × | 原封不动的转发数据包 |
| 普通匿名代理 | 知道你用了代理,可以追查到真实IP | √ | 通常会在HTTP头带上HTTP_VIA和HTTP_X_FRORWARDED_FOR |
| 透明代理 | 真实IP | √ | 会告诉服务器客户端的真实IP 主要作用在于利用缓存提高浏览速度,过滤不安全数据包 |
| 间谍代理 | ? | ? | 用于记录用户传输数据,然后进行研究,达到监控的目的 |
对于爬虫来说,最好是有高匿代理,普通代理对一些小网站也可以用
常见代理设置
| 代理类型 | 稳定性 | 信息 |
|---|---|---|
| 免费代理 | 差 | 可用的不多,使用前最好筛选一下,可以进一步维护出一个代理池 |
| 付费代理 | 较好 | 质量比免费的好很多 |
| ADSL拨号 | 好 | 拨号一次换一个IP,是一种比较有效的解决方案 |
Ajax
AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)AJAX 是一种使用现有标准的新方法
利用JavaScript,在页面不刷新的情况下与服务器交换数据,更新部分网页的技术
这种技术的使用能节约一部分服务器资源消耗,提升用户体验
基本原理
一般来说,从发送Ajax请求到更新网页这个过程可以分为三步:发送请求,解析响应,渲染页面
这里用原生JavaScript作为例子
1 | |
| XMLHttpRequest 对象 | 信息 |
|---|---|
| onreadystatechange | 存储函数(或函数名),每当 readyState 属性改变时,就会调用该函数 |
| readyState | 存有 XMLHttpRequest 的状态 0: 请求未初始化 1: 服务器连接已建立 2: 请求已接收 3: 请求处理中 4: 请求已完成,且响应已就绪 |
| status | 200: “OK” 404: 未找到页面 |
Ajax分析
Ajax头部特点
Ajax有特殊的请求类型xhr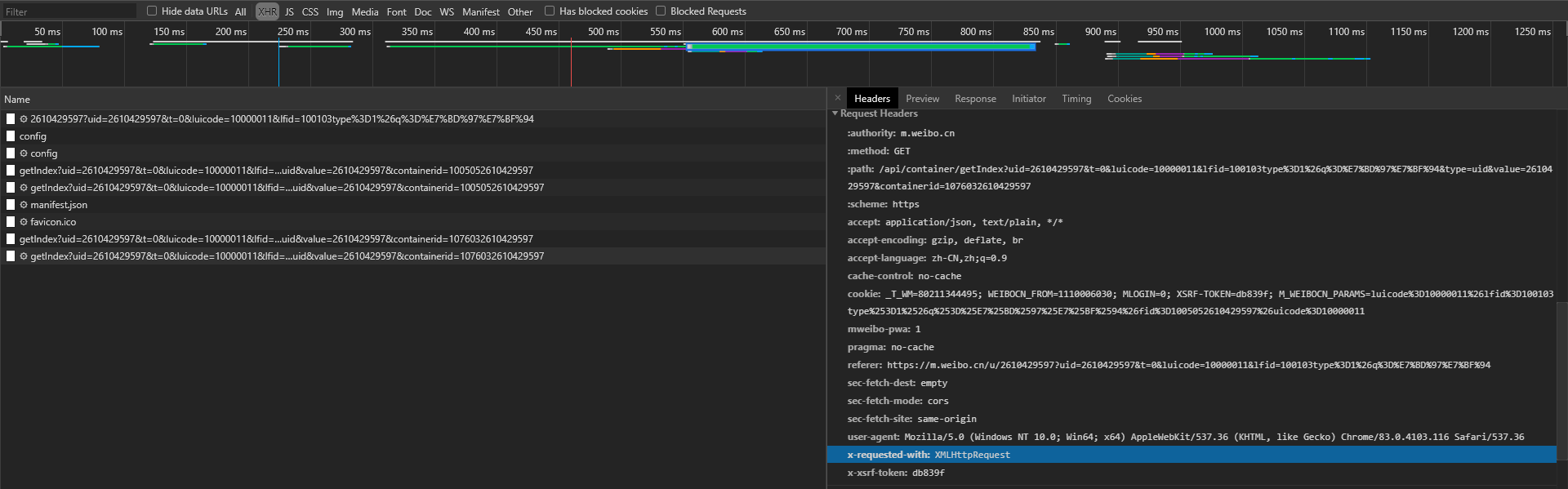
x-requested-with: XMLHttpRequest就标记了此请求是一个Ajax请求
如果需要模拟Ajax发送请求,需要在头部添加这个参数
Ajax结果
返回的结果类型多数会是json/xml/text
其内容可能存在被加密的可能性
但由于在页面上显示是正确的内容,所以js中一定存在解密的逻辑
Ajax溯源
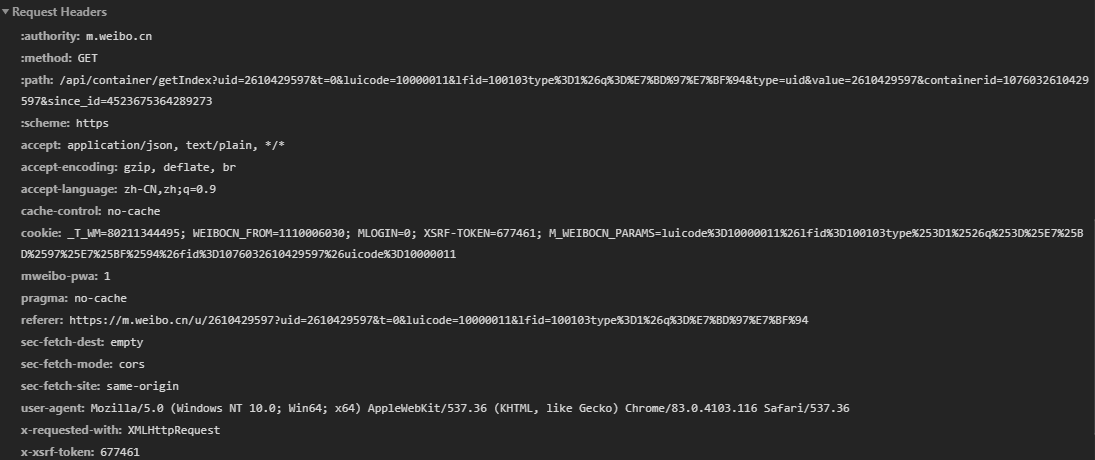
可以根据GET方法的参数来进行全局查找
可以打XHR断点,根据url来寻找
Ajax样式
流星
- AngularJS
1
2
3
4
5
6
7
8
9// 简单的 GET 请求,可以改为 POST
$http({
method: 'GET',
url: '/someUrl'
}).then(function successCallback(response) {
// 请求成功执行代码
}, function errorCallback(response) {
// 请求失败执行代码
});
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!