CSS-反爬
本文最后更新于:2020年9月27日 晚上
CSS
CSS是什么
层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML或XML等文件样式的计算机语言
CSS不仅可以静态地修饰网页,还可以配合各种脚本语言动态地对网页各元素进行格式化
CSS过程
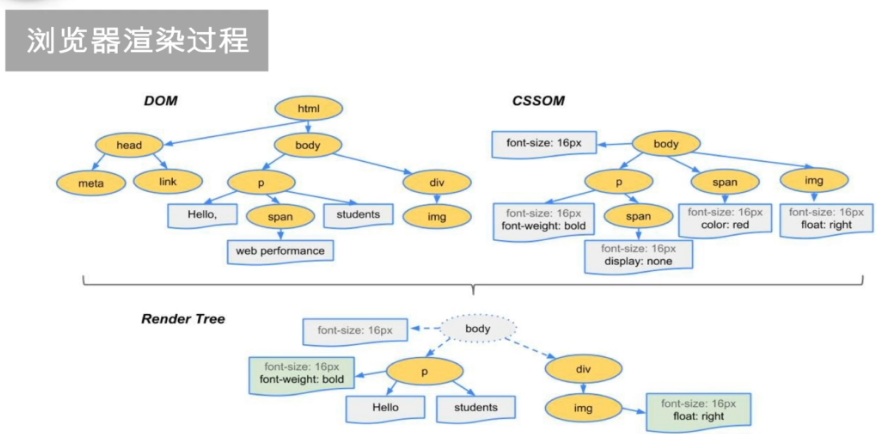
基础语法

伪类:实际上不是真正的类名,而是一个内置影式的有特殊功能的类
CSS反爬
特点
- 成本低
- 只需要前端混淆样式(不需要后台配合)
- 不需要复杂的加密技术
- 不需要验证码,流量监控等额外配置
- 效果好
- 难以识别
- 抓取内容与预期相近
- 反爬措施不易发觉
- 可以弄假数据
- 没有成熟的破解套路
字体反爬
- 字体反爬通常会操作
font-family字段,让其指向自定义的字体 - 通过定义字体的方法,将HTML中用不常见的unicode映射到常用字体中
- 爬虫抓取的数据只能抓到unicode,从而保护了真实数据
应对
- 下载
woff字体文件,转化为tff文件 - 用字体编辑器打开
tff文件,确认unicode与实际值的映射关系 - 将HTML内容按照映射关系进行替换
难点
有些网站会动态生成woff
CSS背景反爬
其原理是CSS Sprite(雪碧图),一种利用一张图做多个效果的操作的技术
在过去,常用于优化网页提升速度。雪碧图的方式只要求请求一次HTTP相比于多次请求来说性能更优
- 数据利用背景图片展示给用户,而不是直接用文本
- 图片包含一张雪碧图,数据利用背景偏移量获取
- 抓取时看不到实际值
应对
- 下载雪碧图,手动检查其对应值
- 调试工具中调整
background-position的偏移量,找到各偏移量与实际值的映射关系 - 在爬虫中获取袁术元素偏移量,将其转为实际值
CSS伪类反爬
- 不直接将内容展现在HTML中
- 通过伪类的
content属性将要展示的值展示出来
难点
获取元素的伪类属性
应对
- 利用
Puppeteer或Selenium在网页中执行JS来获取content1
2
3const el = document.querySelector('.valuable-content') // 利用选择器选出目标元素
const styles = getComputedStyle(el, 'before') // 获取样式(这里可能是before或者after)
console.log(styles.content) // 打印样式查看
元素定位反爬
利用绝对定位将某一个数字或字符将原数字或字符通过一定的偏移量替换
- 替换的数字或字符通常来说是随机的
- 直接抓取会抓到错误信息
应对
计算替换元素偏移量,与被替换元素做比对,还原真实值
1 | |
利用字符分割
- 将字符串用标签分割开来
- 由于其实内联块级(inline-block),依旧是一行展示
- 通常还混淆有不显示的标签(display:none)
应对
将内联块级标签的innerText拼接起来
注意过滤掉所有的display:none属性
1 | |
推荐CSS反爬步骤
- 通过调试工具,人工查看CSS样式
- 判断CSS反爬类型
- 根据不同的类型采用不同的应对措施
- 对于新的CSS反爬,研究其原理,采用合适的反爬策略
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!