编码和加密
本文最后更新于:2021年4月29日 上午
编码
Ascii
ASCII (American Standard Code for Information Interchange)美国信息交换标准代码 是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言
它是最通用的信息交换标准,并等同于国际标准ISO/IEC 646
ASCII第一次以规范标准的类型发表是在1967年,最后一次更新则是在1986年,到目前为止共定义了128个字符
码表
在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0)
例如,像a、b、c、d这样的52个字母(包括大写)以及0、1等数字还有一些常用的符号(例如*、#、@等)
在计算机中存储时也要使用二进制数来表示,为了记录具体用哪些二进制数字表示哪个符号,人们建立了码表。每个人都可以约定自己的一套编码方式(码表)
为了让大家互相通信而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了ASCII编码,统一规定了上述常用符号用哪些二进制数来表示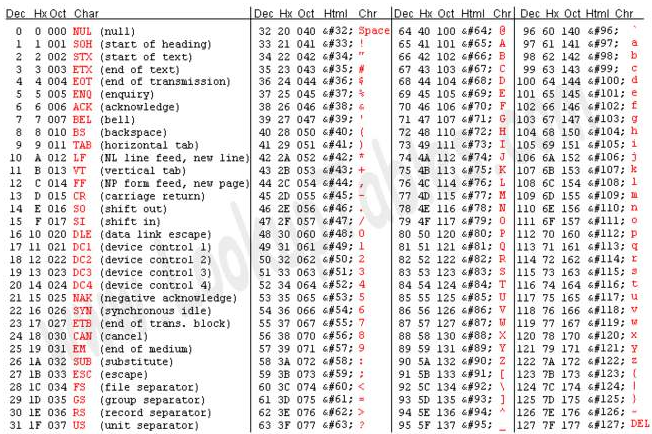
相互转换
1 | |
Base64
Base64是一种基于64个可打印字符来表示二进制数据的方法
是网络上最常见的用于传输编码方式之一3个字节 = 8位 = 24比特, 对应于4个Base64单元
即3个字节可以由4个可打印字符来表示
可打印字符:A-Z、a-z、0-9 (一共62个字符)
剩余两个字符在不同的系统中表示不同
多用于处理文本数据 与 二进制数据的表示、传输、存储
例如:网页上的图片
例: 输入6666
由于后面还没够3字节,所以就会补充一些字符

Base64核心原理是将二进制数据进行分组,每 24Bit/3字节 一大组,再把大组的数据分成 6Bit 的小分组
由于6Bit数据只能表示64个不同字符(2^6=64),所以叫Base64
大厂会自己定制特定的字符表,来达到混淆的目的
虽然都是base64, 但其个字符与值的关系是被更改过的
码表
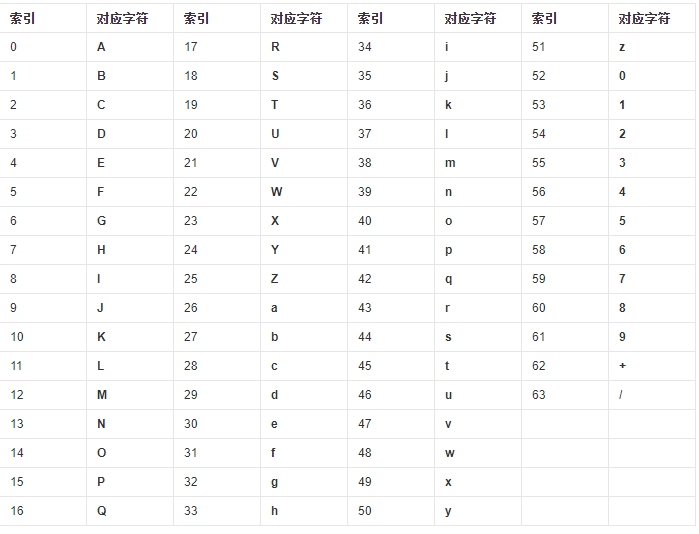
默认的码表是 大写字母 + 小写字母 + 数字 + '+' + '/'
这东西其实能自己定义
浏览运行过程
1 | |
Unicode
Unicode,中文又称万国码、国际码、统一码、单一码,是计算机科学领域的业界标准
它整理、编码了世界上大部分的文字系统,使得电脑可以用更为简单的方式来呈现和处理文字
Unicode 为每一个字符而非字形定义唯一的代码(即一个整数)
换句话说,统一码以一种抽象的方式(即数字)来处理字符,并将视觉上的演绎工作(例如字体大小、外观形状、字体形态、文体等)留给其他软件来处理,例如网页浏览器或是文字处理器
设计原则
- Universality:提供单一、综合的字符集,编码一切现代与大部分历史文献的字符
- Efficiency:易于处理与分析
- Characters, not glyphs:字符,而不是字形
- Semantics:字符要有良好定义的语
- Plain text:仅限于文本字符
- Logical order:默认内存表示是其逻辑序
- Unification:把不同语言的同一书写系统(scripts)中相同字符统一起来
- Dynamic composition:附加符号可以动态组合
- Stability:已分配的字符与语义不再改变
- Convertibility:Unicode与其他著名字符集可以精确转换
文种平面
Unicode字符分为17组编排,每组称为平面(Plane),而每平面拥有65536(即216)个代码点
然而目前只用了少数平面
| 平面 | 始末字符值 | 中文名称 | 英文名称 |
|---|---|---|---|
| 0号平面 | U+0000 - U+FFFF | 基本多文种平面 | Basic Multilingual Plane,简称BMP |
| 1号平面 | U+10000 - U+1FFFF | 多文种补充平面 | Supplementary Multilingual Plane,简称SMP |
| 2号平面 | U+20000 - U+2FFFF | 表意文字补充平面 | Supplementary Ideographic Plane,简称SIP |
| 3号平面 | U+30000 - U+3FFFF | 表意文字第三平面 | Tertiary Ideographic Plane,简称TIP |
| 4号平面 至 13号平面 | U+40000 - U+DFFFF | (尚未使用) | |
| 14号平面 | U+E0000 - U+EFFFF | 特别用途补充平面 | Supplementary Special-purpose Plane,简称SSP |
| 15号平面 | U+F0000 - U+FFFFF | 保留作为私人使用区(A区) | Private Use Area-A,简称PUA-A |
| 16号平面 | U+100000 - U+10FFFF | 保留作为私人使用区(B区) | Private Use Area-B,简称PUA-B |
实际,光是 BMP基本多文种平面 就已经非常够用了,现在绝大多数的常用语言都能在这里找到(包括中文)
编码方式
目前实际应用的统一码版本对应于UCS-2,即使用 16位 的编码空间。也就是每个字符占用2个字节
I004900000000 01001001知77e501110111 11100101
这样理论上一共最多可以表示 2^16 = 65536 个字符
基本满足各种语言的使用
实际上当前版本的统一码并未完全使用这16位编码,而是保留了大量空间以作为特殊使用或将来扩展
实现方式
Unicode的实现方式不同于编码方式
一个字符的Unicode编码确定。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同
Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)
I004900000000 01001001知77e501110111 11100101
严格按照UCS-2会浪费空间,因为英文只需要一个字节就能够表示出来
那一长串的 0 没有记录与传输的必要,因此有了不同的实现方式(比如UTF-8)
Unicode转换样例
1 | |
其它
Unicode 定义了一些奇怪的字符在里面,比如:
http://www.unicode.org/emoji/charts/full-emoji-list.html#1f600
UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对 Unicode 的可变长度字符编码,也是一种前缀码
其设计的主要目的是在能正常使用所有字符的同时,减少常用字符(主要指英文/拉丁文)编码长度
编码规则
- 单字节的字符,字节的第一位设为0,对于英语文本,UTF-8码只占用一个字节,和ASCII码完全相同;
- n个字节的字符(n>1):
第一个字节的前n位设为1
第n+1位设为0,后面字节的前两位都设为10,这n个字节的其余空位填充该字符unicode码,高位用0补足
I=0049=00000000 01001001→01001001知=77e5=01110111 11100101→11100111 10011111 10100101
你会发现,UTF-8 编码对于 Unicode字符码 本身较短的字符较为友好,而对于较后的则并不友好(甚至一顿操作后还变长了)
百分号编码-URL编码
百分号编码(英语:Percent-encoding),又称:URL编码(URL encoding)是特定上下文的 统一资源定位符URL 的编码机制,实际上也适用于 统一资源标志符URI 的编码
字符类型
- URI允许字符
- 保留字符
保留字符存在特殊含义 - 未保留字符
未保留没有特殊含义
- 保留字符
- URI不允许字符
保留字符与未保留字符
保留字符:! * ' ( ) ; : @ & = + $ , / ? # [ ]
未保留字符: 大小写字母,09数字,` - _ . `
URI中的其它字符必须用百分号编码
如果希望使用保留字符,那么必须要经过百分号编码
|!|#|$|&|'|(|)|*|+|,|/|:|;|=|?|@|[|]|
|–|–|
|%21|%23|%24|%26|%27|%28|%29|%2A|%2B|%2C|%2F|%3A|%3B|%3D|%3F|%40|%5B|%5D|
其它字符
建议先转换为UTF-8字节序列, 然后对其字节值使用百分号编码
二进制数据
应该表示为8位一组的序列,然后对每个8位组按照上述方式百分号编码. 例如,字节值0F (十六进制)应表示为%0F
MD5
信息指纹
MD5信息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value)
多用于确保信息传输完整一致
特点
输入任意长度的信息,经过处理,都会输出128位的信息(信息指纹)
获取
1 | |
更多信息
MD5是不可逆的,是不能算回原文的
网上所谓的破解只是弄了一个超级大的数据,把绝大多数常用的东西算出来MD5结果,你输入什么就返回什么
MD5的抗碰撞性已经被人破解
简单而言,就是能根据一个MD5值,通过一些算法,快速得得到一些内容,其MD5结果与原本MD5一致
校验码一致,内容不一致,使得校验的安全性无法确定
加密
加密算法类别
对称加密算法
一方通过秘钥将信息加密后,将密文传给另一方,另一方通过相同的秘钥解开密文得到明文
非对称加密算法
A要向B发送消息,A与B都要昌盛一对用于加密和解密的公钥和私钥,公钥用于加密,私钥用于解密
各自的私钥各自保密,各自的公钥对对方公开
- A要发送信息时,A用B的公钥加密信息
- A将密文用B公钥加密过后的信息发送给B
- B收到密文后,用B自己的私钥解密密文
对于B发送给A的信息也一样
由于只有私钥能够解密,这个过程中所有其它收到密文和公钥的人都无法解密信息
区别与实际
| 对称加密算法 | 非对称加密算法 | |
|---|---|---|
| 安全性 | 较低 | 较快 |
| 处理速度 | 较快 | 较慢 |
常见的情况是:将 对称加密的秘钥 用 非对称加密公钥 进行加密,接收方使用 非对称加密私钥 解密得到 对称加密的秘钥,然后双方使用 对称加密 进行通信
AES
AES高级加密标准(Advanced Encryption Standard,AES),又称Rijndael加密法,是美国联邦政府采用的一种区块加密标准
AES是对称秘钥加密中最流行的算法之一
AES是DES的替代品
要素
秘钥
支持三种秘钥长度128/192/256
秘钥越长,越安全,但是处理速度也越慢
填充 Padding
AES并非一股脑将明文加密成密文的,而是把明文拆分成一个个独立的明文块(一块128bit)加密的
如果一段明文拆开多个块后,最后一个块没到128bit,那么久需要对明文块进行填充
常见填充类型
- NoPadding
要求明文本身就符合分块要求,不允许不符合要求的明文 - ZeroPadding
用0进行填充,填充到位数够为止
并不推荐使用,当文明快最后一位是0时,解密可能出错 - PKCS7Padding
推荐使用
假设数据长度需要填充n(n>0)个字节才对齐,那么填充n个字节,每个字节都是n;如果数据本身就已经对齐了,则填充一块长度为块大小的数据,每个字节都是块大小
工作模式
AES的工作模式,体现在把明文块加密成密文块的处理过程中
AES加密算法提供了五种不同的工作模式CBC、ECB、CTR、CFB、OFB
模式之间的主体思想是相似的,在处理细节上有区别
ECB模式
最简单的模式,此模式下,每个明文块的加密都是独立的,互不干涉的
优点是简单快捷,有利于并行计算
缺点是明文相同的块会变成相同的密文块,安全性比较差
CBC模式
CBC模式引入了一个新的概念:初始向量IV
初始向量IV
其作用与 MD5加盐 类似,目的是为了防止 同样的明文块 被加密成 同样的密文块
CBC模式在每一个明文块加密前会让明文块和一个值做异或操作
IV作为初始化变量,参与第一个明文块的异或,后续的每一个明文块和它前一个明文块所加密出来的密文快相异或
最终得到 同样的明文块 被加密成 不同样的密文块
优点:安全性被提高
缺点:无法并行计算,性能不比ECB。引入了IV增加了复杂度
流程
- 把明文按128bit拆分为多个明文块
- 按照选择的填充方式填充最后一个明文块
- 每一个明文块利用AES加密器和秘钥加密成密文块
- 拼接所有的密文块,得到结果
示例
简单的过程表示
secret = encrypt(key_type, message)
输入 加密信息,明文,得到加密结果
message = decrypt(key_type, message)
输入 加密信息,密文,得到明文信息
常用的对称加密算法
| 算法 | 秘钥长度 | 工作模式 | 填充模式 |
|---|---|---|---|
| DES | 56/64 | ECB/CBC/PCBC/CTR/… | NoPadding/PKCS5Padding/… |
| AES | 128/192/256 | ECB/CBC/PCBC/CTR/… | NoPadding/PKCS5Padding/PKCS7Padding/… |
秘钥的长度越长,加密越安全,但处理速度越慢
工作模式与填充模式可以看做是对称加密算法的参数和格式选择
1 | |
编码与加密常识
基础通识
- MD5
提取结果通常是 32 位,不受明文长度影响 - Base64
编码结果末尾通常会出现一或二个等于符号,受明文长度影响 - SHA1
加密结果值为 40 位,不受明文长度影响 - SHA256
加密结果值为 64 位,不受明文长度影响
盲猜技巧
- 一长串无规律数字与字母组合的字符大概率是 AES、DES、SHA 相关加密
- 另外,AES、RSA 等对称和非对称加密都喜欢将结果值用 Base64 进行编码,这样易于传递
- 如果你看到一长串字符里出现
+、\和末尾的=,那大概率就是上一行描述的加密算法加密后又进行了Base64编码的结果 - 32 位的字符串有概率是
MD5摘要结果 - 64 位的字符串有概率是
SHA加密结果
通过全局搜索找寻可疑字符串,在所有文件中寻找关键字
在需要的地方打上断点,找寻到目标的加密逻辑
复现做法
在找寻到以后,可以选择:
- 参照js逻辑用其它语言重新实现
- 直接调用js的加密函数
从非常长的 javascript文件 中归纳逻辑,建议将一些关键的变量或者函数复制粘贴到另一个 javascript文件 中,运行以后根据 没有定义 的报错 来逐一补全所需,直到得到结果
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!