Scrapy-Reids-爬虫
本文最后更新于:2020年9月27日 晚上
信息
Scrapy本身并不支持分布式。要做分布式爬虫,就需要借助Scrapy-Redis组件。
这个组件利用了Redis可以分布式的功能,使得Scrapy能够进行分布式爬取,提高爬虫效率。
分布式爬虫的优点:
可以充分利用多台机器的IP,带宽,CPU等资源
分布式爬虫的问题:
如何保证不会出现重复爬取。
如何正确的将数据整合到一起。
运行流程
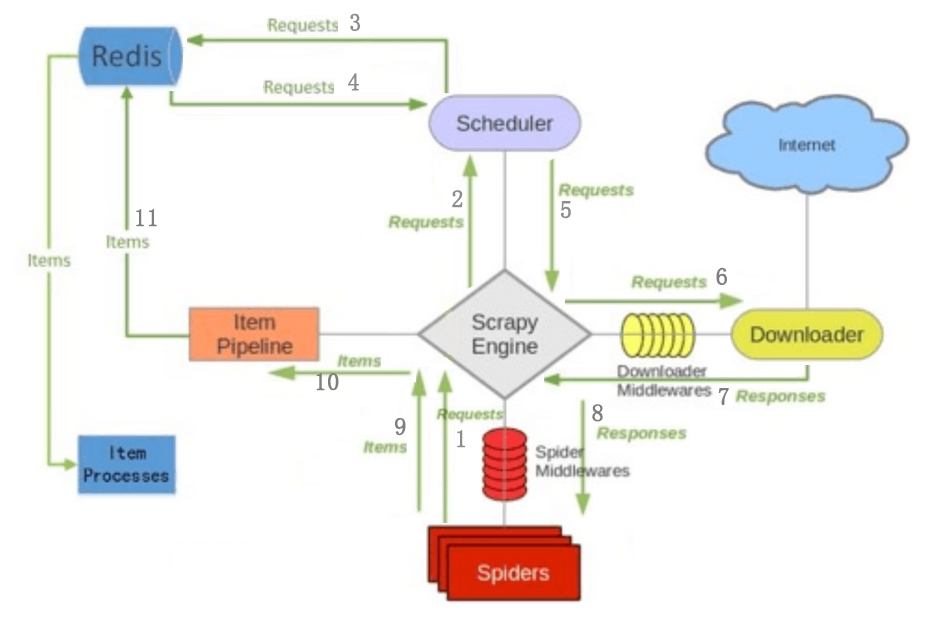
Engine从Spider中得到第一个Requests进行爬取ENGIN将Request放入SCHEDULER调度器,并且获取下个Request- 为保证不会进行重复爬取,
SCHEDULER调度器Requests发送去Redis - 若
Redis中无爬虫记录,返回Requests到SCHEDULER调度器 SCHEDULER将Requests返回给ENGINE(因为ENGING进行任务调度)ENGINE发送Requests到Downoader,通过Downloader Middlewares进行处理(这一步进行Http请求,返回response)- 通过
Downloader Middleware进行资源下载(就是html信息),如果下载完成,通过Dowloader生成一个Resonse并且发送给ENGINE ENGINE从DOWNLOADER接收Resonse,并将Resonse发送给Spider进行处理。Spider通过Spider Middleware进行处理ResponseSpider处理Response并且返回items和新的Requests给ENGINE,这部分处理通过Spilder Middleware进行处理ENGINE从Spider接收items,并将items发送给Item Pipeline进行处理Item Pipeline将items发送给redis保存下来
一般部署
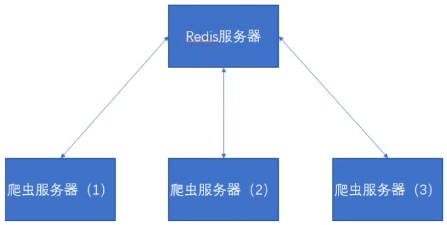
Redis服务器:
内存要大,只用作记录爬取下来的数据和URL去重
爬虫服务器:
执行爬虫代码,进行爬取,获取数据发送给Redis服务器
文档
github地址:https://github.com/rmax/scrapy-redis
文档及其简单,只给了基础设置和一个例子项目。
基础
安装
1 | |
setting
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!