Splash-js渲染-爬虫
本文最后更新于:2020年10月16日 下午
Splash是什么?
Splash是一个javascript渲染服务。
它是一个带有HTTP API的轻量级Web浏览器,使用Twisted和QT5在Python 3中实现。
QT反应器用于使服务完全异步,允许通过QT主循环利用webkit并发。
是Scrapy推荐使用的javascript渲染
能起到和web driver相似的功能。
只能在 Linux 与 Mac 系统下安装
文档
官方文档:https://splash.readthedocs.io/en/latest/install.html
网友中文文档:https://splash-cn-doc.readthedocs.io/zh_CN/latest/scrapy-splash-toturial.html
安装
此服务需要Docker才能安装
安装Docker
需求:Docker版本≥17拉取splash
1
sudo docker pull scrapinghub/splash启动
1
sudo docker run -itd -p 8050:8050 scrapinghub/splash有些时候docker会抽风,无法连接,重启一下
docker就好service docker restart
要是觉得太麻烦,可以在启动时添加启动参数1
docker run -p 8050:8050 --restart=always -d scrapinghub/splash- -d 后台运行
- –restart=always 崩溃后自动重新启动
测试服务
浏览器中输入网址http://localhost:8050/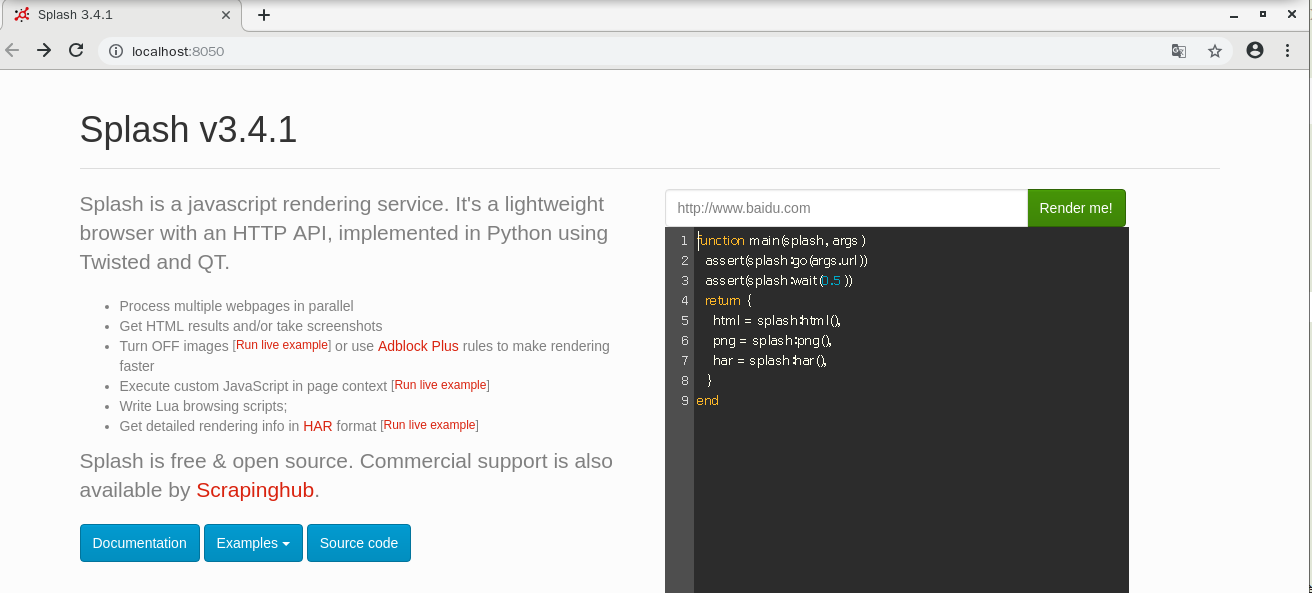
若是见到欢迎界面,那么久成了运行好了以后,要是防火墙做好了设置,服务器外也能通过
ip:端口的形式在浏览器访问到了入门
首页
在首页看到的界面里的代码时Lua语言代码
点击Render来渲染指定的网页,并返回结果Splash提供的http接口
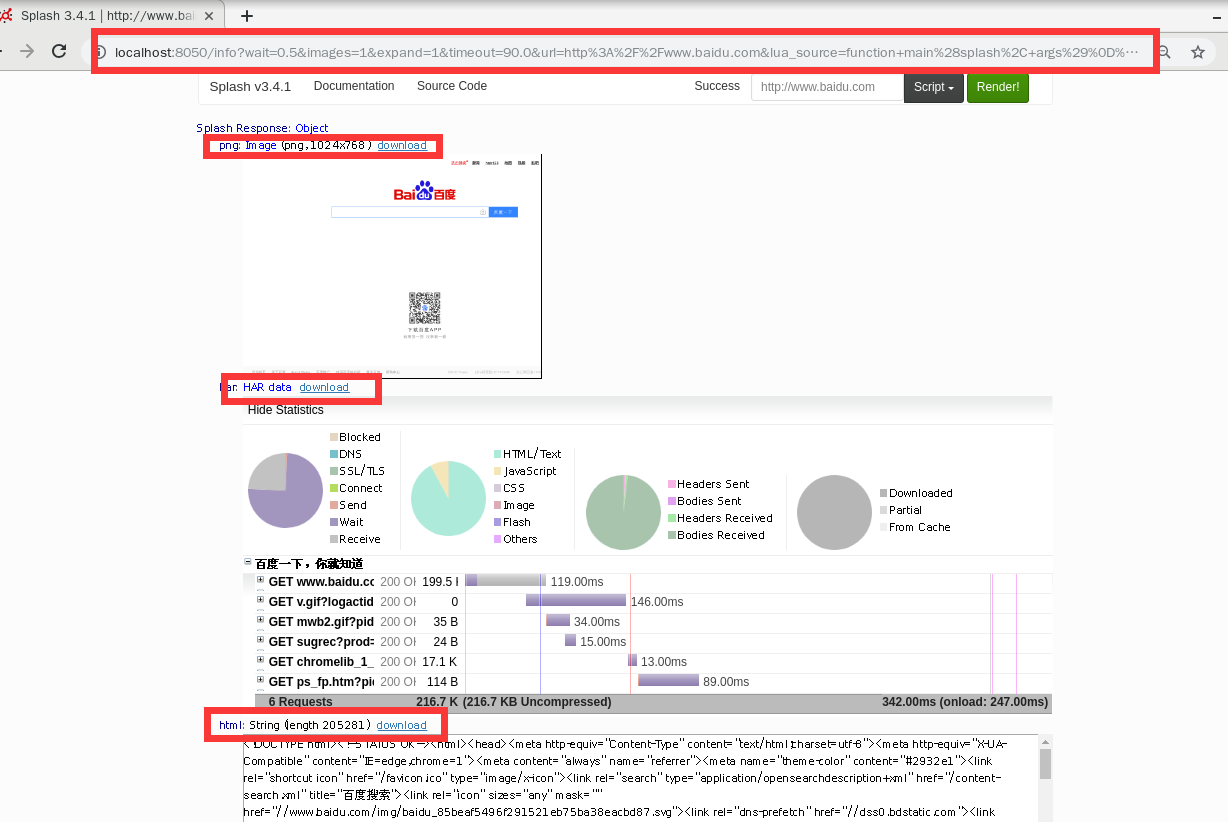
信息 意义 url restful风格url对于抓取网页,最重要的是 render.html虽然这个演示中并没有一般来说请求类似这样http://localhost:8050/render.html?url=http://www.baidu.com/&timeout=30.0&wait=0.5 参数解读:url:请求的地址* timeout:选填,超时时间* wait:选填,页面加载完毕后,等待的时间png 渲染效果截图 HAR HTTP Archive format:用来记录浏览器加载网页时所消耗的时间的工具。记录每一个HTTP请求发出直到收到完整的HTTP响应中间所耗费的时间,可以迅速帮助我们知道是哪些HTTP请求没有得到及时的回复,从而进行更一步的排查。 html 网页html 通过shell进行
1
curl 'http://localhost:8050/render.html?url=http://www.baidu.com/&timeout=30.0&wait=0.5'效果就类似于
get请求一般,返回来的html是已经渲染好了的。1
curl 'http://localhost:8050/render.html?url=http://www.baidu.com/&timeout=30.0&wait=0.5' -X POST如果要发送
post请求的话,这样就可以了。通过python进行
使用方法很简单,就是像普通的请求那样请求本地的Splash即可
1
2
3url = 'http://localhost:8050/render.html?url=http://www.baidu.com/&timeout=30.0&wait=0.5'
response = request.get(url)
print(response.text)使用
Scrapy的话,有专门的Scrapy插件:Scrapy-splash更多
其实
splash不止于渲染,能实现一些浏览器一般的操作,诸如鼠标点击,键盘输入都不在话下。
不过,要想实现这些,就需要编写lua代码来实现。
可以在python中写好lua代码,通过参数传递过去。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!